

Posts
Want to hear about our latest learnings?Subscribe to get notified.
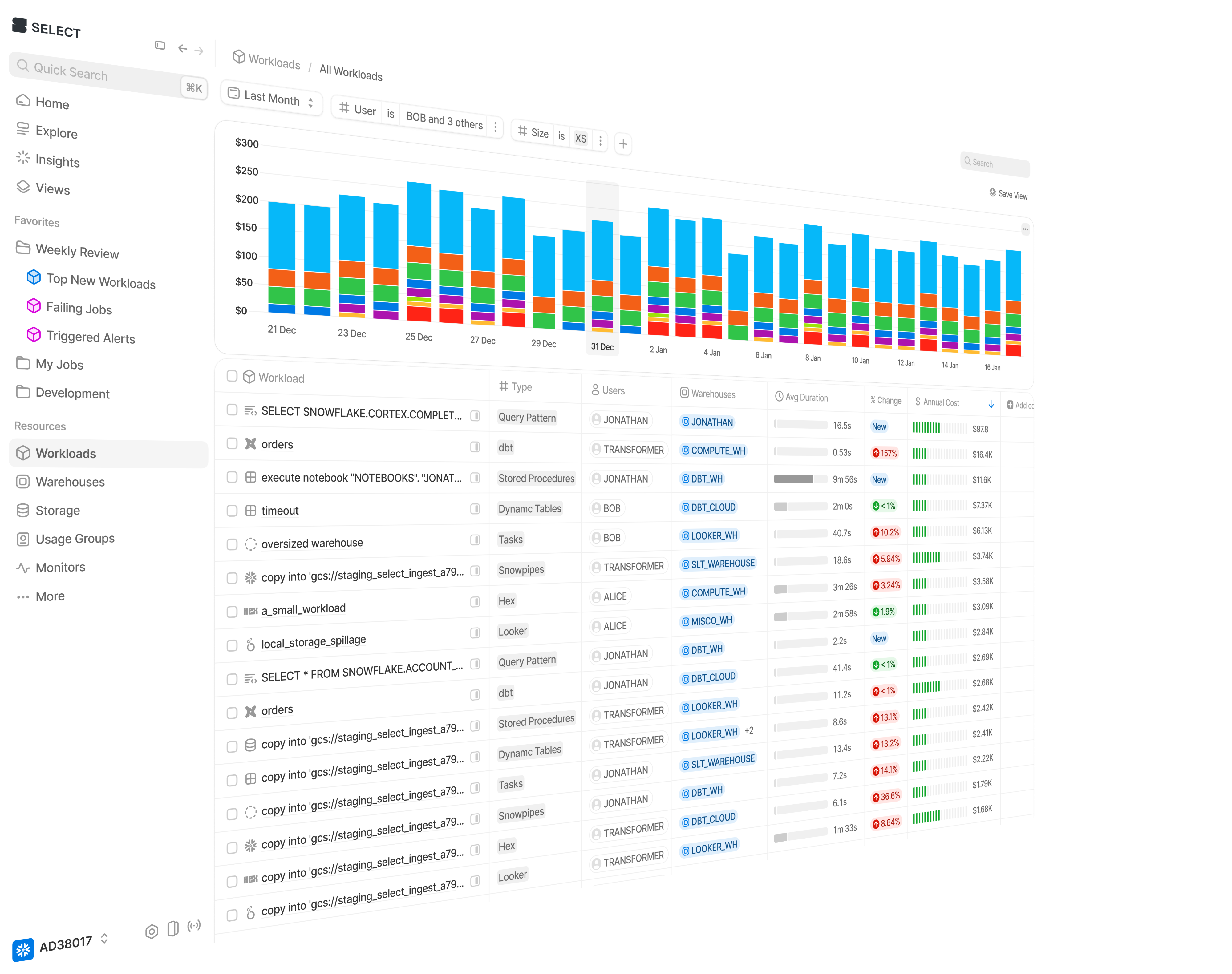
Get up and running in less than 15 minutes
Connect your Snowflake, Databricks, or BigQuery account and instantly understand your savings potential.


Want to hear about our latest learnings?Subscribe to get notified.
Connect your Snowflake, Databricks, or BigQuery account and instantly understand your savings potential.