

Analyzing your DAG to identify unused dbt models in Snowflake
Jay SobelMonday, August 21, 2023
Why care about unused dbt models?
One of the easiest ways to reduce unnecessary Snowflake spend is to get rid of things that aren't being used. In a previous post on identifying unused tables in Snowflake, Ian explained how Snowflake’s Account Usage views can be used to introspect Snowflake object usage to ultimately identify and remove tables that aren't being actively queried, allowing users to save on storage costs. When it comes to tables that are created and continuously updated by ELT tools like dbt, the potential savings from removing these tables is much higher, as users will save on the compute costs associated with creating and updating the table in addition to the storage costs.
If your dbt project has been around for over a year, it's quite likely that you'll have a number of dbt models that are no longer being used, but are still running every day and driving compute costs. If you're looking for a quick win to both lower your costs and improve the cleanliness of your data warehouse, this post is for you!
Understanding dbt model usage
In this article I’ll expand on the premise of understanding Snowflake object usage to specifically capture dbt model usage. This requires one additional model to represent the relationship between dbt models (the DAG, as a table) so that intermediate models with 0 direct usage aren’t flagged as unused, so long as their downstreams have some query activity. I recommend starting with the original post, at least to get familiar with the account_usage schema.
To understand why we can’t use the approach from that blog post to identify unused dbt models, consider the following DAG:
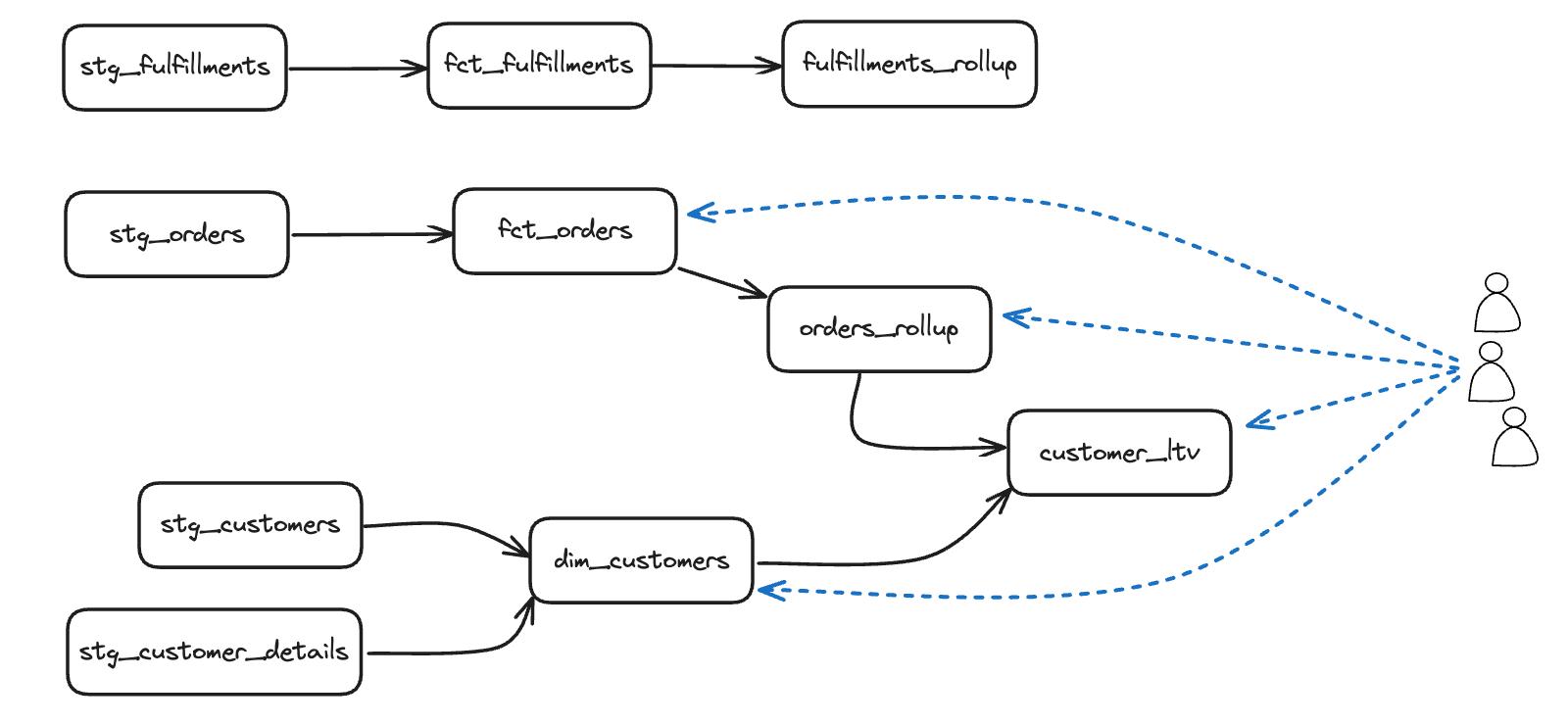
If we were to query for unused tables we would initially identify every table as having some usage, but that usage would be from dbt itself running tests, or building downstream models. Once we exclude queries run by dbt, we might correctly identify the top row; stg_fulfillments, fct_fulfillments and fulfillments_rollup as unused models, but our output would also claim the entire stg_ layer is unused. In dbt, direct usage is not the only concern. We also need to consider the usage of downstream dependents.
We can do this by building a model that captures dbt model descendants, and then do some clever aggregation of queries ‘upwards’ over these DAG dependencies.
An overview of the approach
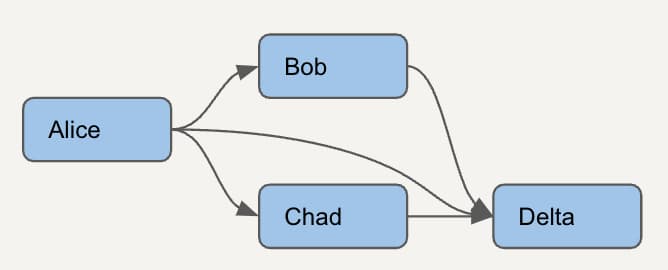
Let's consider an even simpler DAG with just 4 models. In order to properly identify unused dbt models, we first need to understand which models rely on each other.
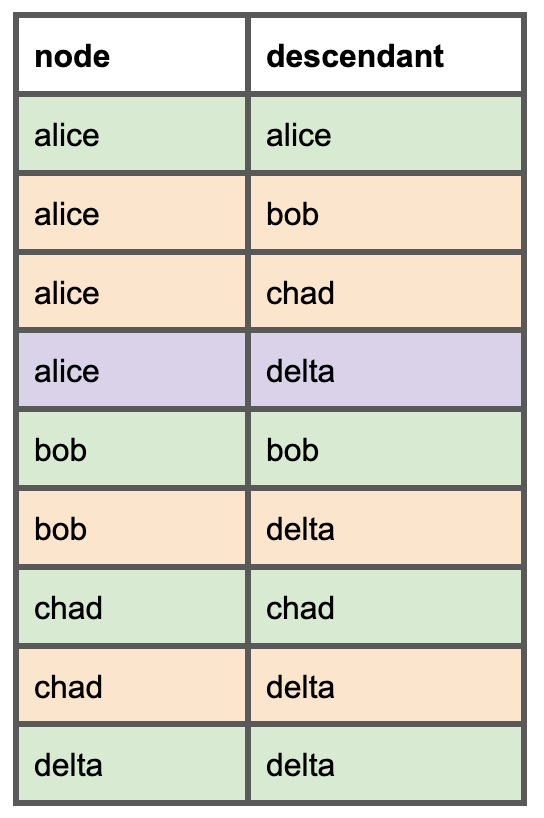
For each model, we need to list all the downstream models. Here's how this simple DAG will look in the new dependencies model we'll create. The green rows are a node-and-itself, the orange rows are direct parents, and the purple row shows that a direct parent can also be an indirect parent.
Once we have this model, we can do things like determine whether the Alice model can be safely removed by checking the usage on the downstream dependencies: Bob, Chad, and Delta.
Prerequisites
To determine which tables are being used, we’ll leverage the models discussed in the previous article. Both of these are available in the dbt-snowflake-monitoring package built & maintained by SELECT.
dbt_snowflake_monitoring/models/query_base_object_access.sqldbt_snowflake_monitoring/models/query_history_enriched.sql
For our model of dbt dependents, we’ll be building something new: dbt_model_descendants. This can be derived from dbt-snowflake-monitoring or more accurately via dbt_artifacts if you have it set up. I’ll provide SQL for either source:
- Option 1:
dbt_snowflake_monitoring/dbt_queries.sql - Option 2:
dbt_artifacts/dim_dbt__current_models.sql
How to model dependencies in your dbt DAG
Step 1: get each model's parents
Our first step is to derive a table with one row for each dbt model with an array column capturing the model’s direct parents.
| node | table_sk | parent_array |
|---|---|---|
| customer_activity | prod.analytics.customer_activity | [”customers”, “events”] |
| events | prod.analytics.events | [”stg_events”] |
| ... | ... | ... |
To build this dataset, there are two options.
Using dbt_snowflake_monitoring
The first option is to use dbt_snowflake_monitoring/dbt_queries.sql, which you should have already have installed for the other required mdoels (query_base_object_access, query_history_enriched). The two main drawbacks of this option are that deleted models will continue to be included for a couple days after they leave the project, and that sources are never included, because they are not "refs".
Using dbt_artifacts
The second option is to use dbt_artifacts/dim_dbt__current_models. This is the more robust option, but requires the dbt_artifacts package which has a more complicated set-up process.
Step 2: Derive node children
Now that we have a list of nodes, we will create a new CTE, node_children by flattening the nodes CTE. This maps out the "first degree parents".
Using dbt_snowflake_monitoring
Using dbt_artifacts
Step 3: Recursively find all model descendants
The rest of the query is the same regardless of whether you're using dbt-snowflake-monitoring or dbt-artifacts. It carries out the following steps:
- Derive
node_descendants_recursive(all degrees) by recursively joiningnode_children(from above) to itself - The granularity at this point is "all paths"
- Union an additional row for "a node and itself"
- Aggregate
node_descendantsto unique node-descendant pairs
Here's the query assuming you are using dbt-snowflake-monitoring:
Head to the appendix for a version of this query you can leverage in your dbt project.
How to query for unused dbt models
With our new dbt_model_descendants model we created that accounts for model dependencies (or should we say descendencies?) we can aggregate direct table usage and distribute it upward through the DAG. This looks like a join of query counts on the descendant side, conditionally aggregated around the parent. The self-edge comes into play here as the conditional aggregation can differentiate direct vs indirect usage by checking if the descendant is actually the node itself.
This query tells us how many "usage" queries directly hit each dbt model, as well as how many usage queries are distributed across a model’s downstream descendants. If a model has total_queries = 0 then it’s both not serving direct usage, and not supporting any downstream direct usage. Do note that downstream_queries and total_queries will be higher than your actual total Snowflake query count since a single query can be counted across more than one mode.
What to do with unused models
As an analytics engineer, I know more about building new tables than I do about deleting old ones.
Most dbt models are fixed transformations of raw data that can be switched off and on without "missing" anything. Sure the production model will go stale until the model is turned back on, but there will be irretrievable loss of information. In these cases, simply disabling the model, or deleting it and letting it live on in your git history are both good options. I’d recommend also dropping the table at this stage, just to avoid any users accessing stale data.
Models like dbt snapshots, or other fancy incremental schemes might not fit this description. Deprecating something in this category is going to require more case-specific considerations, but having been in this position, I know it’s also probably likely that nobody knows what the model is for, or even what its intentions are.
How to remove a dbt model from your project
Steps for deleting a model:
- Delete the
.sqlmodel file.
Ctrl+Shift+Fsearch the model’s name in the whole project to find…refs()to the model- schema or congi
.ymlreferences to the model.
- Drop the corresponding Snowflake table (or view)
You probably won’t have to update a ref() if you’re using this approach because any model referencing an unused model must also be unused (or else the parent would have downstream usage!). If there is a chain of unused models, I’d recommend starting at the end and working backwards; in A -> B -> C, delete C first!
Disabling a model is a quick way to turn off a model without deleting any code. Disabled models act like they don’t exist, but their code stays in your project; it’s just a config line;
This might be the quickest and easiest-to-reverse way to shut off a model, but assuming you’re using git already, you wouldn’t be losing any of the code you delete, either. And assuming you’re concerned with model sprawl, you’re probably better off taking unused models out to the dumpster, rather than declaring a dedicated trash corner.
Lastly, make sure to thank your models for their hard work. As the great Data Engineer Marie Kondo says;
Cherish the [analytical models] that bring you joy, and let go of the rest with gratitude.
Appendix - files for your dbt model project

Jay is a Senior Analytics Engineer at Ramp, one of the fastest growing startups in the US. Jay has nearly a decade of data analysis & engineering experience, spanning many fast growing technology companies like Gopuff, Drizly, Wanderu and LevelUp. Jay is a passionate member of the dbt and Snowflake community, regular contributing to optimization and general best practice discussions.
Want to hear about our latest data cloud learnings?Subscribe to get notified.
Get up and running in less than 15 minutes
Connect your Snowflake, Databricks, or BigQuery account and instantly understand your savings potential.

