

dbt Threads: The easiest way to speed up your dbt project in Snowflake
Niall Woodward & Ian WhitestoneMonday, January 29, 2024
One of the first configuration settings dbt users look to when seeking to understand and improve dbt project run times is threads. Why does this parameter have such a big influence and what should you set it to? We'll explain it all in this short post.
If you’re short on time, the TL,DR answer to the question of how you should set the threads value is “as high as is needed to ensure queueing”. 16 should achieve that for the typical dbt project, and you can confirm by checking the queries tab in Snowflake while a run is in progress.
What does the dbt threads parameter control?
Background on multi-threading in Python
At its core, dbt is essentially a Python process which takes your SQL ("model") files and runs them against whatever data warehouse you are using (i.e. Snowflake in the context of this post).
By default, Python is single threaded, meaning it can perform one operation at a time. With dbt, all the "hard work" of processing your data is happening in Snowflake. As a result, the dbt Python process is largely I/O bound. It spends most of its time sitting and waiting for Snowflake to run the SQL it sends. For I/O bound applications, Python developers can use multi-threading to speed up their applications. Multi-threading allows you to spin up multiple threads, where each thread can perform its own operations, effectively allowing you to run your processes in parallel instead of one at a time.
What are dbt threads?
dbt exposes this functionality through a parameter called threads. This parameter controls how many threads are spun up by dbt to execute the necessary SQL operations for your project in parallel.
To summarize it more simply: the threads parameter controls the maximum number of models that will get sent to Snowflake for execution at any given time.
Snowflake Virtual Warehouse Design & Concurrency Implications
For a quick recap on Snowflake's virtual warehouse compute architecture, each node in a Snowflake warehouse contains 8 cores/threads that are available for processing your query. An X-SMALL warehouse has 1 node, and therefore 8 cores/threads. A Small warehouse has double that number (2 nodes, 16 cores), a Medium has double the amount of a Small (4 nodes and 32 cores), and so on.
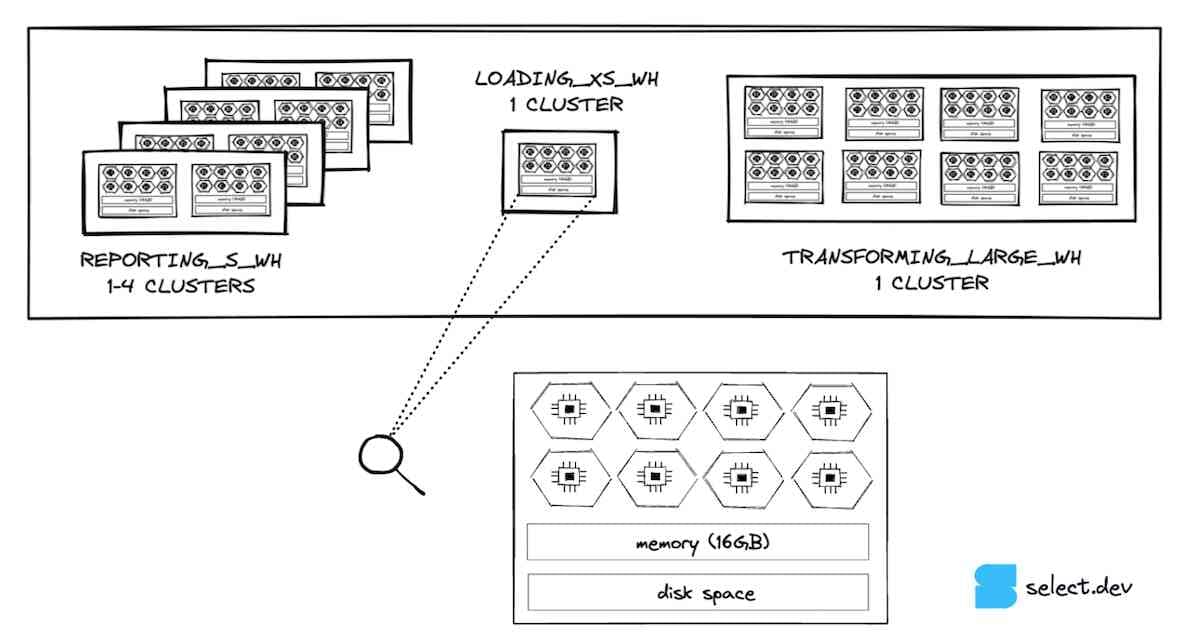
If we consider an X-SMALL warehouse, it can run up to 8 queries simultaneously at any point in time. As the warehouse size increases, the potential for concurrency (the number of queries that can be run simultaneously) also increases.
So, while the dbt threads parameter will control how many queries it sends to Snowflake in parallel, the Snowflake virtual warehouse itself will control how many queries it actually processes in parallel. When a warehouse cannot process any more queries, it will put them in a queue and automatically process them when there is available compute capacity.
What is the impact of dbt threads on run time?
dbt projects are DAGs (Directed Acyclic Graphs), and they’re often quite big and complex, with one model being depended on by several others, and vice-versa.
A way we find helpful to explain the impact of threads is to imagine the two extremes.
If we start by supposing only a single thread has been set, then the run duration of a project with 500 models is going to be the sum of the individual durations of every model. That’s going to take a long time, and the virtual warehouse or warehouses running the models are going to spend a lot of that time under-utilized (you can read more about warehouse utilization here). The result is a very slow project and correspondingly high virtual warehouse costs.
Let’s now imagine what would happen if we chose a number of threads that is far higher than the number of models that could ever run simultaneously, due to the number of models in the DAG and their dependency structure. By doing this, we’ve ensured that dbt will try to execute all the queries that are possibly eligible to run at any given moment. This shifts the bottleneck on the dbt project’s run time from each model’s run time (except single node dependencies) to the computational throughput of the virtual warehouse, ensuring utilization efficiency is maximized. This will achieve two things:
- Queueing (which means all the available warehouse compute is being used)
- Minimized end-to-end project run times
In this scenario, it’s likely that individual model run times will increase as resource contention comes into play, but remember that the goal here is end-to-end run time. For batch jobs, queueing is a good thing because it means you’re getting best value for money.
How many dbt threads should you use for Snowflake?
Based on the discussion above, we recommend you set the dbt threads parameter to a high enough value to ensure there is queueing on your warehouse, as this will. A value of 16 will achieve this for most dbt projects, but you should validate that the virtual warehouse you use for dbt is fully saturated by ensuring there is some query queuing.
Here's an example of a dbt model timing chart with over 16 threads. You can see that Snowflake can handle running many dbt resources in parallel.
Impact on queuing
There are several ways to check for query queuing. One method is using the Warehouse Activity graph on the warehouses page in the Snowsight UI, which gives you a quick overview of how often there is queueing in the warehouse. In this screenshot from our dbt project, there is consistent queueing in the warehouse we use for dbt, which is exactly what we want since it gives us confidence that the warehouse is being fully utilized. As long as your project run time is within the SLA, the queuing should not be a concern.
What other factors affect dbt run times?
Once the dbt threads have been configured to make sure the bottleneck is the Snowflake computational throughput, there are a few other techniques that can be used to improve dbt run times. Follow the links below to learn more:
- Model incrementalization
- Optimizing your query by understanding bottlenecks in the Snowflake query profile
- Warehouse size and multi-cluster configuration

Niall is the Co-Founder & CTO of SELECT, a SaaS Snowflake cost management and optimization platform. Prior to starting SELECT, Niall was a data engineer at Brooklyn Data Company and several startups. As an open-source enthusiast, he's also a maintainer of SQLFluff, and creator of three dbt packages: dbt_artifacts, dbt_snowflake_monitoring and dbt_query_tags.

Ian is the Co-founder & CEO of SELECT, a SaaS Snowflake cost management and optimization platform. Prior to starting SELECT, Ian spent 6 years leading full stack data science & engineering teams at Shopify and Capital One. At Shopify, Ian led the efforts to optimize their data warehouse and increase cost observability.
Want to hear about our latest data cloud learnings?Subscribe to get notified.
Get up and running in less than 15 minutes
Connect your Snowflake, Databricks, or BigQuery account and instantly understand your savings potential.

