

Every Major Announcement at Snowflake Summit 2023 and 1 Word Never Mentioned
Ian WhitestoneWednesday, July 05, 2023
Niall & I attended our first Snowflake Data Cloud Summit in 2022 and were blown away by the energy and momentum behind the platform. We knew we needed to start building around this thriving ecosystem, and SELECT was born.
Last week we returned to Las Vegas for our second summit, and it did not disappoint. Snowflake came out with some new major announcements, and shared a plethora of other new features to a packed room at Caesar's Palace. In this post we dive into the latest innovations, share our thoughts on each, and talk about the 1 thing they did not mention.
Native Applications Framework (Public Preview)
Hands down, the biggest announcement of Summit 2022 was the Native Applications Framework (Native Apps). This year, it went into Public Preview.
Imagine if every time you wanted to download an app on your iPhone, you had to go to a different website, learn about the offering, then give that company direct access to your phone. That’s how every company using Snowflake currently works with vendors today.

Native Apps aims to bring an experience like the iPhone app store to the Snowflake Data Cloud. Rather than Snowflake customers letting vendors connect to their data warehouse and pull their data out in order to serve it back to them in a separate application (just like we do at SELECT), Native Apps will allow vendors to run their applications directly in the customer’s Snowflake account. This has several benefits:
- Better security. Data never leaves your warehouse, and no one outside of your company gets access to it. You also won’t need to manage separate logins or access to the 3rd party application. Native Apps will leverage the same authentication and permission set as the rest of your Snowflake account.
- Simpler legal procurement. Most vendor relationships involve a new contract that must be reviewed by an in-house legal team. With Native Apps, legal teams will only need to review the Snowflake marketplace terms once, not for each app installed.
- Your bill becomes much simpler as everything gets charged through Snowflake. Snowflake even announced the ability for customers to pay for apps using their existing contract capacity, a feature called capacity drawdown.
At SELECT we’re incredibly excited about the promise of Native Apps, as they will allow us to help even more Snowflake customers maximize their Snowflake ROI and unlock valuable insights by streamlining onboarding and procurement. It will also allow for easier data sharing of all the unique cost and performance datasets we create.
Snowpark Container Services (Private Preview)
Snowpark Container Services (SCS) stole the show at Summit 2023. Towards the end of the keynote, Christian Kleinerman walked everyone through 10 live demos of applications with different use cases running natively in Snowflake using SCS.

Snowpark Container Services will let you truly run any workload or application in Snowflake. How will this work? Docker. By allowing users users to deploy a Docker container directly into Snowflake with SCS, users will no longer be limited by the language runtimes and environments that Snowflake supports.
Snowpark Container Services will support a variety of different workloads. Complex AI models can be trained and deployed in SCS, and leverage new GPU instances. A scheduled job or service function can be run in a Snowpark container. Or a long running service, like a web application, can be hosted directly in SCS and run on Snowflake 24/7. Hex demoed their slick notebooks UI (a complex, React web application) running directly in a Snowpark container.
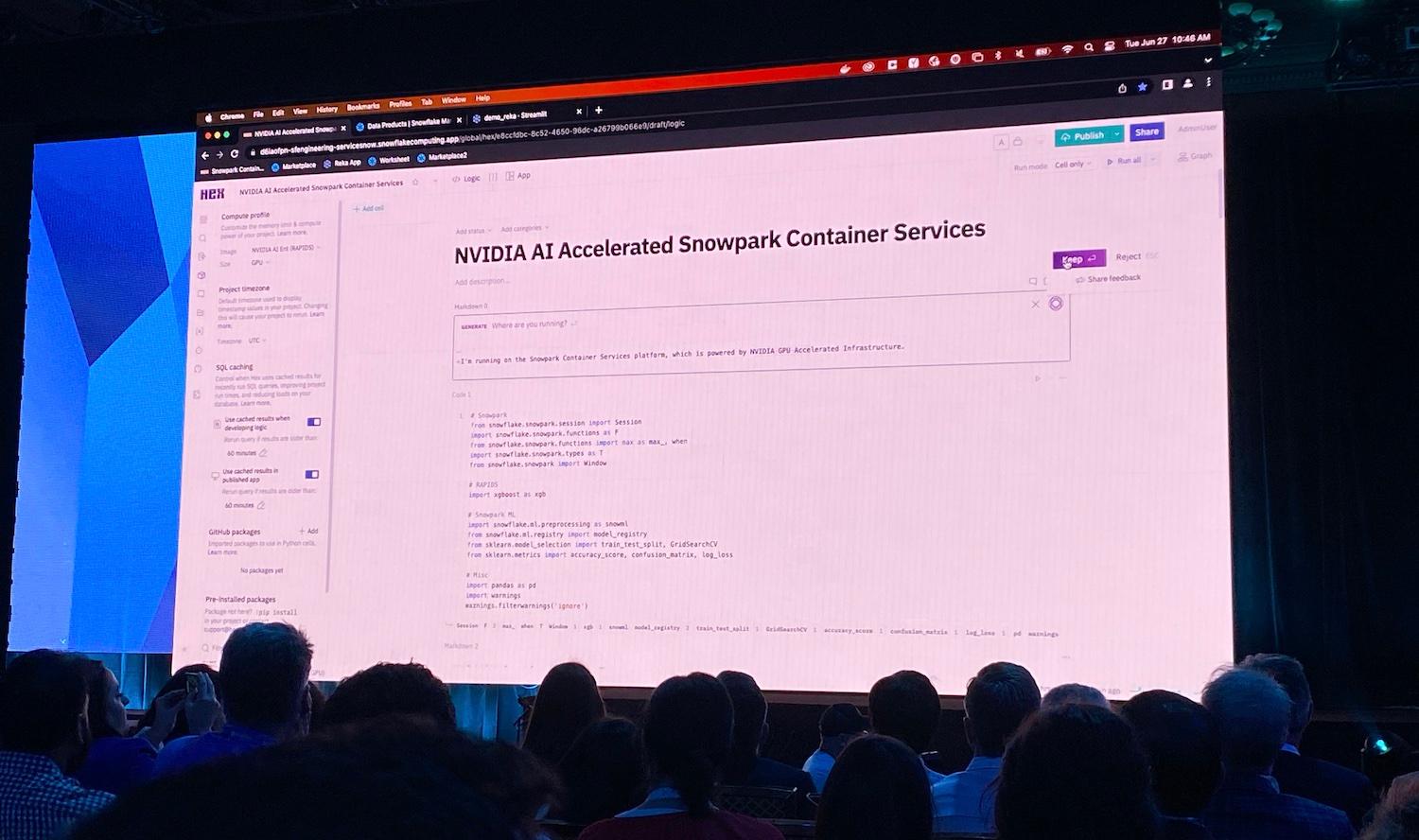
A service running 24/7 in Snowflake sounds expensive, but rest assured, they will be announcing new types of compute instances for SCS to make these services cost effective.
Managed Iceberg Tables (Private Preview)
Why Iceberg?
Many companies already have lots of their data sitting in cloud storage, but not loaded into Snowflake. Wouldn’t it be great if you could use Snowflake to both query and update these datasets?
Apache Iceberg is an open table format designed for analytic datasets. This table format is an abstraction layer on the physical data files (think, Parquet files) that supports ACID (atomicity, consistency, isolation, durability) transactions, schema evolution, hidden partitioning, and table snapshots, and other features. Query engines need to know which files make up a given “table”, and Iceberg provides this.
Snowflake’s existing support for Iceberg
Up until last year, Snowflake’s only option for querying data lake files was their read-only external tables. Querying these tables generally had worse performance than tables stored directly in Snowflake, due to a variety of factors. At Summit 2022, Snowflake announced support for Iceberg Tables, meaning that customers could manage their data lake catalog with Iceberg, and get much better performance with Snowflake’s query engine due to the metadata that Iceberg provides. In addition, Iceberg support means customers can treat their external (Iceberg) tables like regular Snowflake tables with updates, deletes and inserts.
Summit 2023 Iceberg announcement
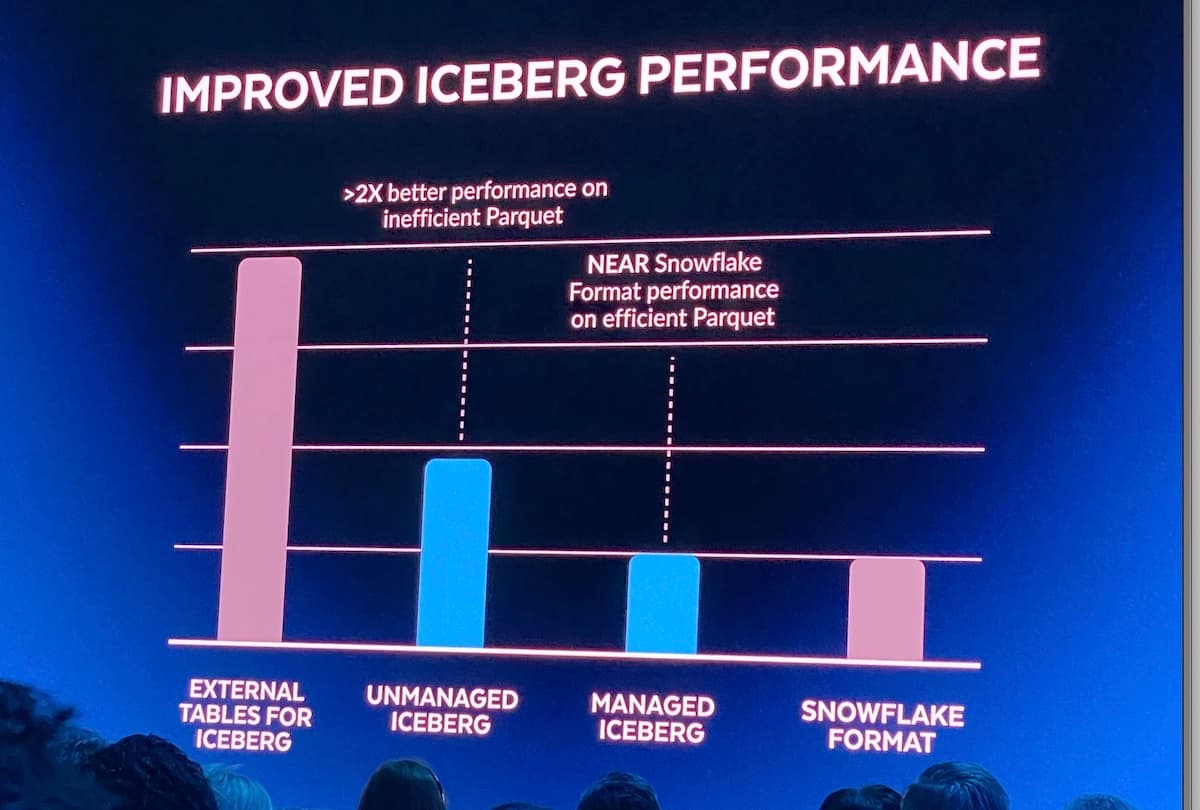
A remaining challenge with using Iceberg is that you need a system which can continually write and update the Iceberg metadata in a separate catalog. To help solve this, Snowflake announced “managed iceberg tables” at Summit 2023. Users can now leverage Snowflake compute resources to manage the Iceberg data. In addition to abstracting away this burden, users should also see performance improvements.
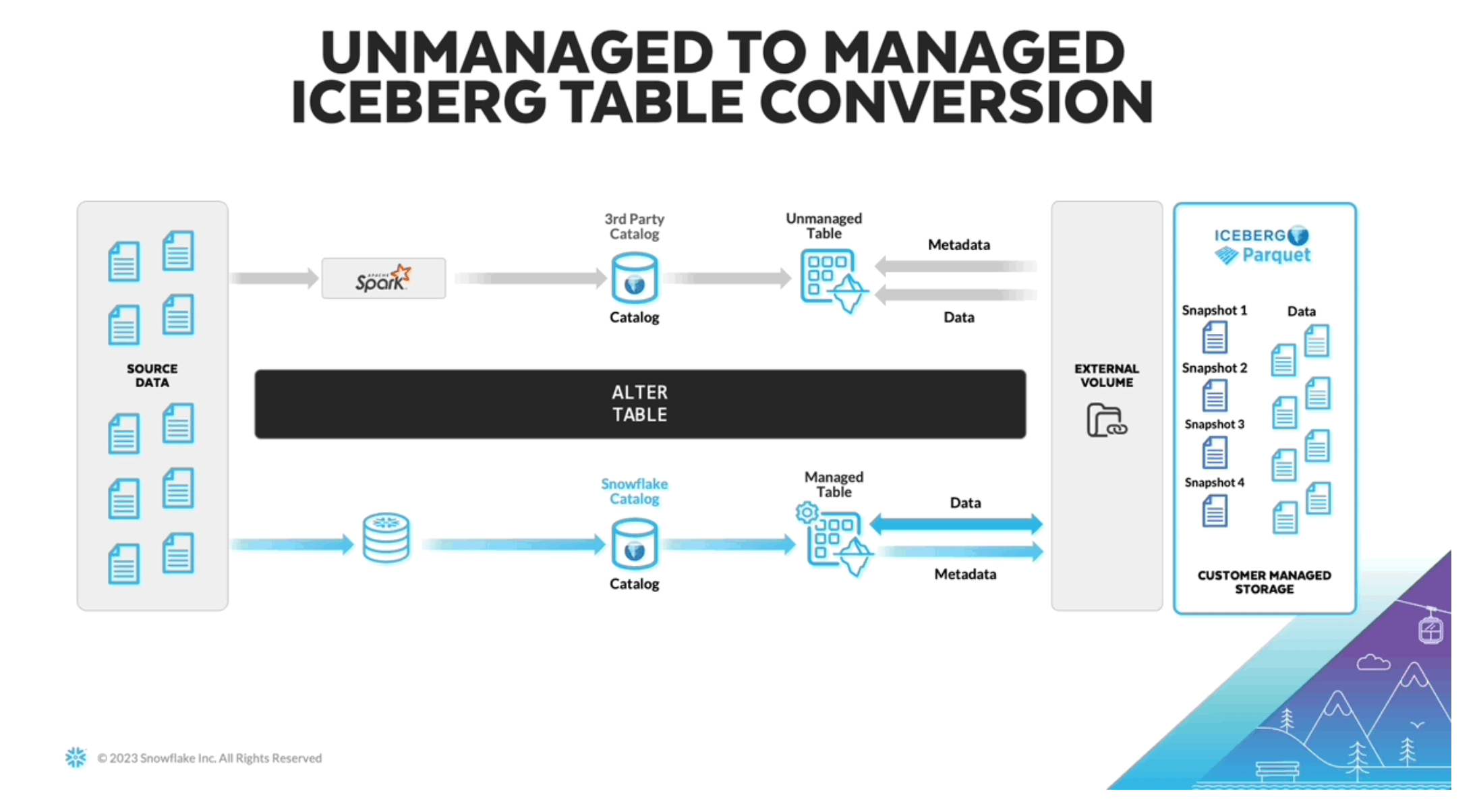
Based on the absence of any product documentation, I believe this feature is currently in private preview. The image above was sourced from James Malone on LinkedIn. For those new to Iceberg, I found this blog post to be a good primer.
Dynamic Tables (Public Preview)
One of the biggest data transformation cost drivers we see with customers on Snowflake, including our own account, comes from fully rebuilding tables each time the data pipeline runs. Tables get built this way because it’s both faster and easier. Incrementally building a table is more nuanced as you have to consider factors like late arriving data, the correct high watermark to use when filtering each dataset, and more. Data pipelines can also incur un-necessary costs due to jobs running on a simple schedule that don’t account for when new upstream data gets populated.
Snowflake has long supported Materialized Views (MVs), which help with some of these challenges by only refreshing the table when new data arrives upstream. They come with a number of pitfalls however, a big one being that your SQL view definition cannot support a variety of common operations like joins, unions, aggregations, group bys, or window functions.
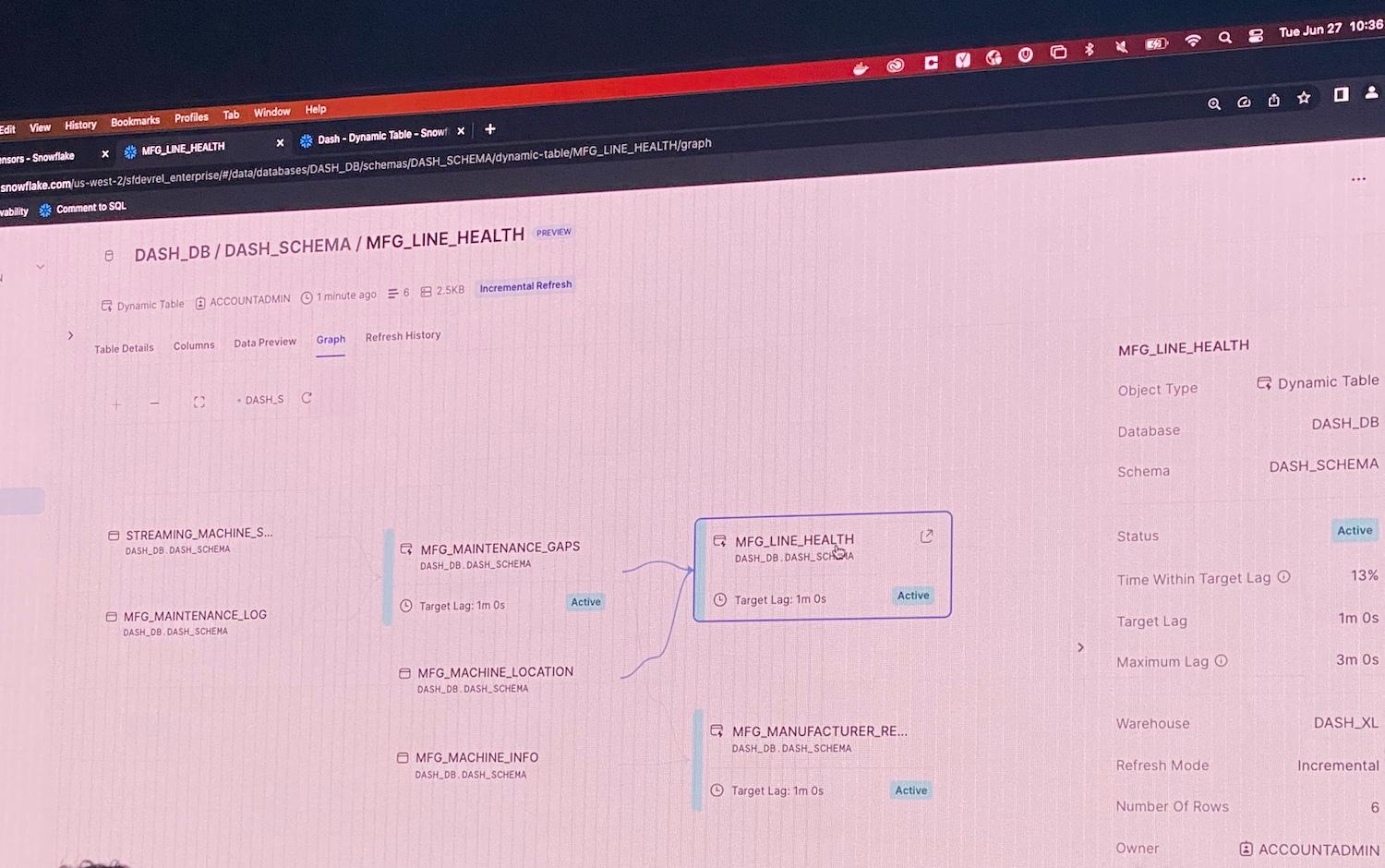
At this year’s Summit, Snowflake announced that Dynamic Tables (DTs) are now in Public Preview. DTs are similar to MVs in that you define your table with a SQL expression, and Snowflake takes care of materializing that expression once there is new data upstream. DTs provide a host of other advantages:

- They have a much wider range of SQL support, and support joins, unions, aggregations, window functions, and more.
- They incrementally process new data, meaning they won’t waste resources re-computing the same data over and over again.
- MVs got very expensive if the upstream table was being frequently updated. With DTs, Snowflake will update them based on a latency parameter you define. This gives users more control over how often these tables update, and in turn, how the associated compute costs.
- They come with first class UI support. Users can easily visualize DTs and their dependencies, and see the historical runs on the
Refresh HistoryTab.
Snowpipe Streaming API (Public Preview)
Snowflake announced that the Snowpipe Streaming API is now in Public Preview. Snowpipe Streaming allows customers to load data into Snowflake directly from Apache Kafka or from a custom Java application. Snowpipe Streaming helps support workloads that require data with lower latency.
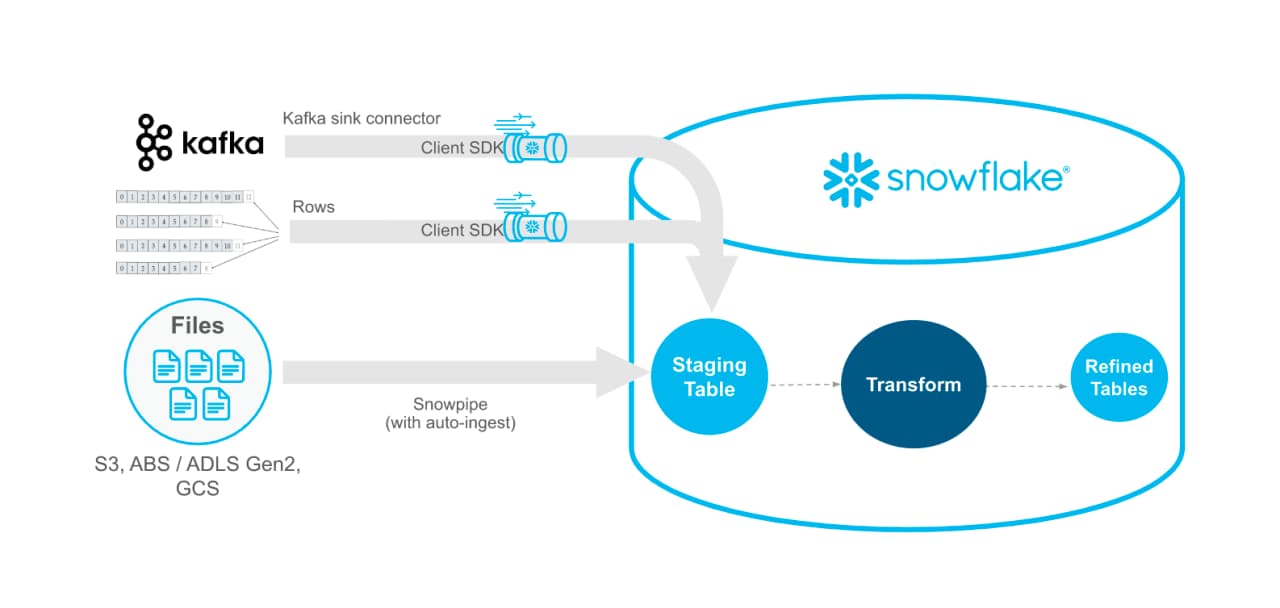
Snowpipe Streaming is also the most cost effective way to load data, once you have the necessary infrastructure in place. Alternative data loading strategies like Snowpipe or manual COPY INTO statements running on a self-managed warehouse both involve loading a file from a stage into Snowflake. By avoiding the expensive read step and file management overhead, Snowpipe Streaming becomes a more cost-effective option.
A bunch of AI announcements
Given all the talk about generative AI and LLMs, it came as no surprise that Snowflake announced a slew of upcoming AI features.
Nvidia Partnership
On the first day of the conference, Snowflake announced a new partnership with Nvidia. Snowflake will team up with Nvidia to integrate Nvidia’s LLM framework NeMo into Snowflake. This will help engineers build large language models directly into Snowflake, using the data they already have stored there.
Snowflake Copilot (TBD)
Snowflake demoed a very cool “comment to SQL” feature, much like Github Copilot. Imagine being able to write a comment like -- show me the count of daily active users over the last 30 days and have Snowflake automatically generate the query for you using its knowledge of (a) your data and (b) the exact Snowflake sql dialect. Snowflake is sitting on the largest possible training dataset of queries so I expect this model to be better than anything you can get off the shelf from other companies.
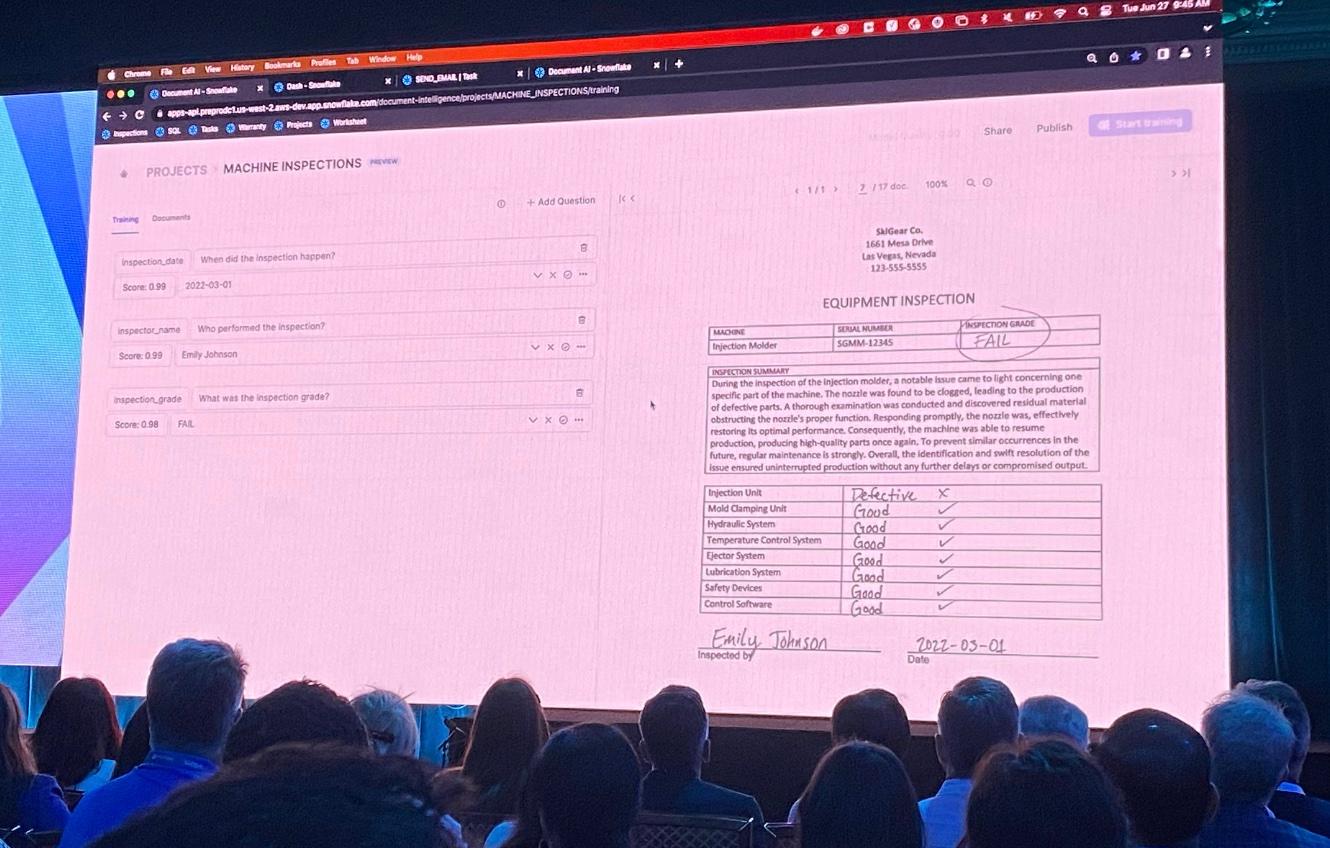
Document AI (Private Preview)
In April 2022, Snowflake acquired a company named Applica which specialized in analyzing unstructured data. At Summit 2023, Snowflake announced a new feature called Document AI that leverages Applica’s technology. This is Snowflake’s first party LLM, and lets you ask questions about documents you have stored in Snowflake.
Snowflake should off a nifty demo where information was automatically pulled out of documents, and users could give feedback on the information retrieved in order to improve the model’s accuracy. Users could then easily deploy the trained model and run it as a UDF in a SQL query.
Various developer updates
Snowflake's product management team announced a slurry of various developer updates. We’ll share more details on these as we receive them:
- A new Snowflake CLI and Python rest API (to complement the existing Snowflake Connector for Python)
- The Snowpark Model Registry, which allows data scientists to store, publish, discover and serve ml models in Snowflake.
- Various Snowpark enhancements, including more granular control of python packages, support for Python 3.9 and 3.10, external network access and vectorized Python UDTFs.
- Three native machine learning powered functions that will help users with forecasting, anomaly detection, contribution explorer.
- New logging and tracing APIs, and automatic synchronization between git and snowflake stages to support developers building in the Native Apps Framework
- Streamlit is apparently “very close” to public preview. They showcased new Streamlit components for building chat experiences.
Cost Optimization and Control
Contrary to what many people think, Snowflake cares deeply about ensuring their customers use Snowflake effectively. Snowflake understands they need to play the long game, and help customers get the most value out of each dollar they spend on Snowflake.
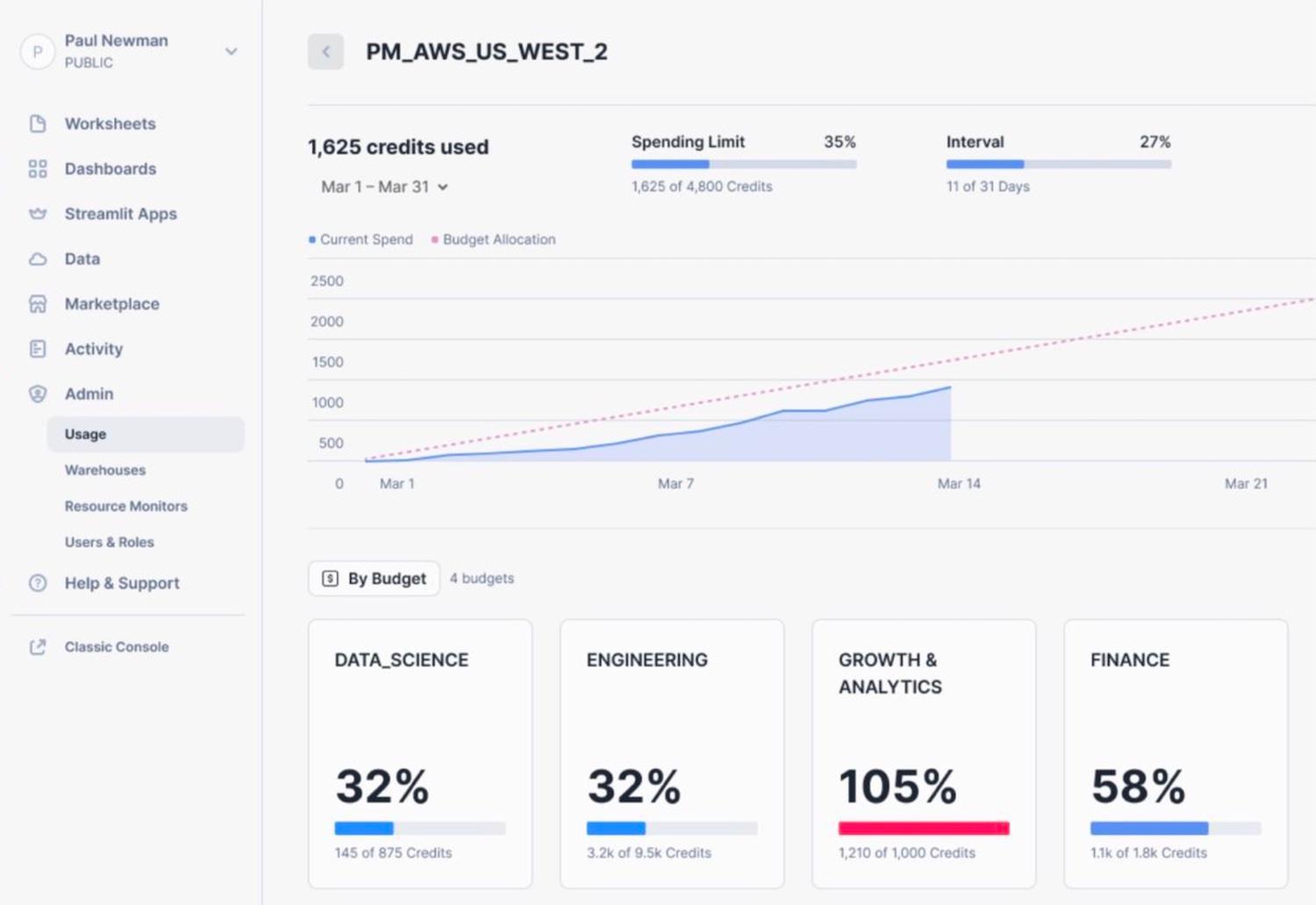
Budgets (Public Preview)
To help customers better control their Snowflake spend, Snowflake announced that their Budgets feature will be going into Public Preview. Before Budgets, users were only able to set resource monitors, which let you specify the number of credits a warehouse or group of warehouses can consume. Budgets go further by allowing you to group together more Snowflake resources (warehouses, tables, materialized views, Snowpipes, etc.) and assign a credit limit (budget) to that resource group. Similar to resource monitors, you can then get alerted or suspend the underlying resources to prevent further charges once the credit limit is reached.
Thanks to Sonny for sharing the details and image below.
Warehouse Utilization (Private Preview)
One of the biggest challenges Snowflake customers face is knowing if their warehouses are sized correctly. To help with this, Snowflake announced a new warehouse utilization metric in Private Preview. We don’t have more details on this one, but will be excited to explore it once available in Public Preview.
Performance Improvements
Snowflake announced a bunch of performance improvements to their query engine and a new Snowflake Performance Index (SPI) they will use to publicly measure and track the improvements they are making. In true Snowflake fashion, all of these improvements are applied automatically and don’t require users to take any action to enable them.

It who must not be named
Engineers and data practitioners are used to working with data stored in different databases. It’s been a nature of our reality ever since the second database was created back in the 70s, and why there’s a multi-billion dollar industry built around data movement (cough Fivetran).
By no means is this desirable. Wouldn’t it be great if you could just use one database for everything? At Summit 2022, Snowflake announced Unistore, a new type of workload that supports transactional & analytical style queries. This was an incredibly ambitious endeavour, as this is a notoriously hard engineering problem.
Unfortunately, there was no mention of Unistore or the hybrid tables that power them under the hood at Summit 2023. We presume this is due to the fact that the engineering team is still working out the kinks with this complex feature prior to opening it up to Public Preview.
Update: several people have reached out and let me know that there was a talk about Unistore in a dedicated session, so apologies for missing that! (With that said, I'm keeping the title as is because it's great clickbait! 😉)

Ian is the Co-founder & CEO of SELECT, a SaaS Snowflake cost management and optimization platform. Prior to starting SELECT, Ian spent 6 years leading full stack data science & engineering teams at Shopify and Capital One. At Shopify, Ian led the efforts to optimize their data warehouse and increase cost observability.
Want to hear about our latest data cloud learnings?Subscribe to get notified.
Get up and running in less than 15 minutes
Connect your Snowflake, Databricks, or BigQuery account and instantly understand your savings potential.

