

Should you use CTEs in Snowflake?
Niall WoodwardWednesday, March 15, 2023
CTEs are an extremely valuable tool for modularizing and reusing SQL logic. They're also a frequent focus of optimization discussions, as their usage has been associated with unexpected and sometimes inefficient query execution. In this post, we dig into the impact of CTEs on query plans, understand when they are safe to use, and when they may be best avoided.
Introduction
Much has been written about the impact of CTEs on performance in the past few years:
- CTEs are pass-throughs - Tristan Handy - 2018-11-07
- Snowflake query optimizer: unoptimized - Dominik Golebiewski - 2021-10-13
- CTE Considerations - bennieregenold7 - 2022-07-22
- A recent dbt Slack thread - 2023-02-22
But the fact we’re still seeing so much discussion shows we’ve not reached a conclusion yet. This post aims to provide a reasoned set of guidelines for when you should use CTEs, and when you might want to avoid them. Snowflake's query optimizer is being continuously improved, and like in the posts linked above, the behaviour observed in this post will change over time.
We'll make use of query profiles to understand the impact of different query designs on execution. If query profiles are new to you or you'd like a refresher, check out our post on how to use Snowflake's query profile.
Let’s start with a recap of what CTEs are and why they’re popular.
What are CTEs?
A CTE, or common table expression, is a subquery with a name attached. They are declared using a with clause, and can then be selected from using their name identifier:
CTEs are comma delimited, meaning we can define several by separating them with commas:
We can also put CTEs inside CTEs if we so wish (though things get a little hard to read!):
Why use CTEs?
The main reasons to use CTEs are:
- CTEs can help separate SQL logic into separate, isolated subqueries. That makes debugging easier as you can simply
select * from cteto run a CTE in isolation. - CTEs provide a way of writing procedural-like SQL in a top-to-bottom style, which can help with code review and maintainability.
- CTEs can help conform to the DRY (don’t repeat yourself) principle, providing a single place to define logic that is referenced multiple times downstream.
How does Snowflake treat CTEs in the query plan?
In order to understand the performance implications of CTEs, we first need to understand how Snowflake handles CTE declarations in a query’s execution.
Are CTEs pass-throughs?
Yes, so long as the CTE is referenced only once. By pass-through, we mean that the query gets processed in the same way whether or not the CTE is used. When a CTE is referenced only once, it’s always a pass-through, and the query profile shows no sign of it whatsoever. Therefore, using a CTE that’s referenced only once will never impact performance vs avoiding the CTE.
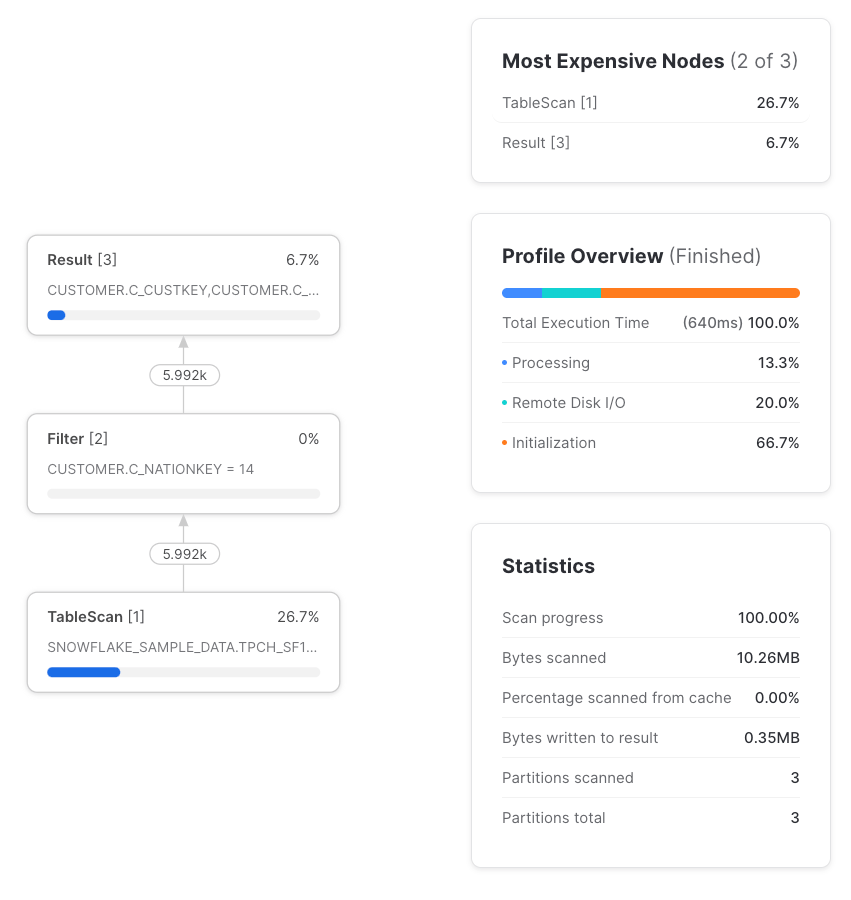
But if we reference that CTE more than once we see something different, and the query’s execution is now different from if we’d referenced the table directly rather than using a CTE.
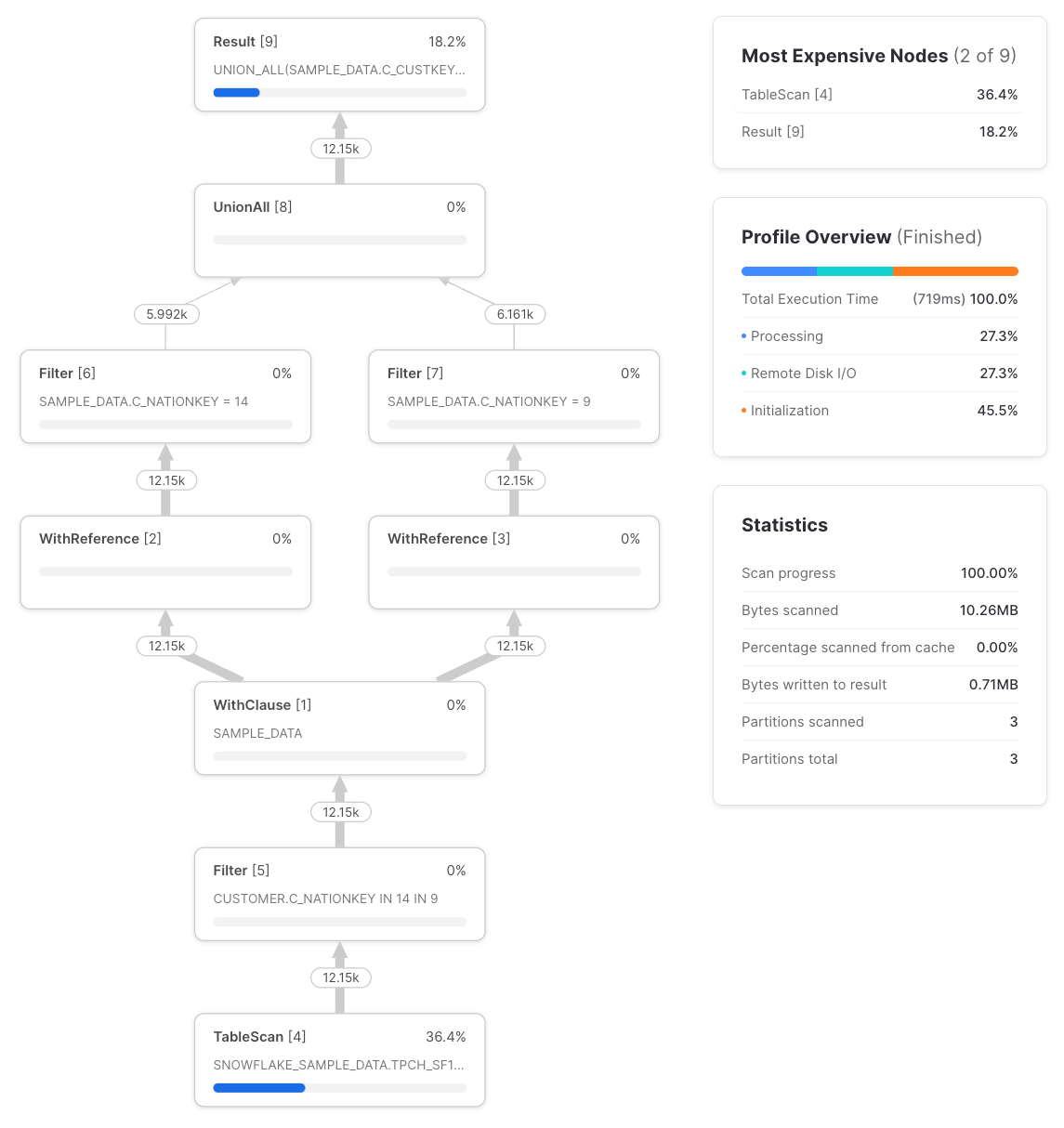
We see two new node types, the WithClause and the WithReference. The WithClause represents an output stream and buffer from the sample_data CTE we defined, which is then consumed by each WithReference node. Note that Snowflake is intelligently ‘pushing down’ the filter in the nation_14_customers and nation_9_customers CTEs to the TableScan before the WithClause. Previously, Snowflake didn’t do this, as reported in Dominik’s post. It’s worth checking that this behavior applies to more complex queries, but for this query, the profile is the same as if we’d written the query like:
Let's now replace the sample_data CTE references with a direct snowflake_sample_data.tpch_sf1.customer table reference, and see the differences in execution plan:
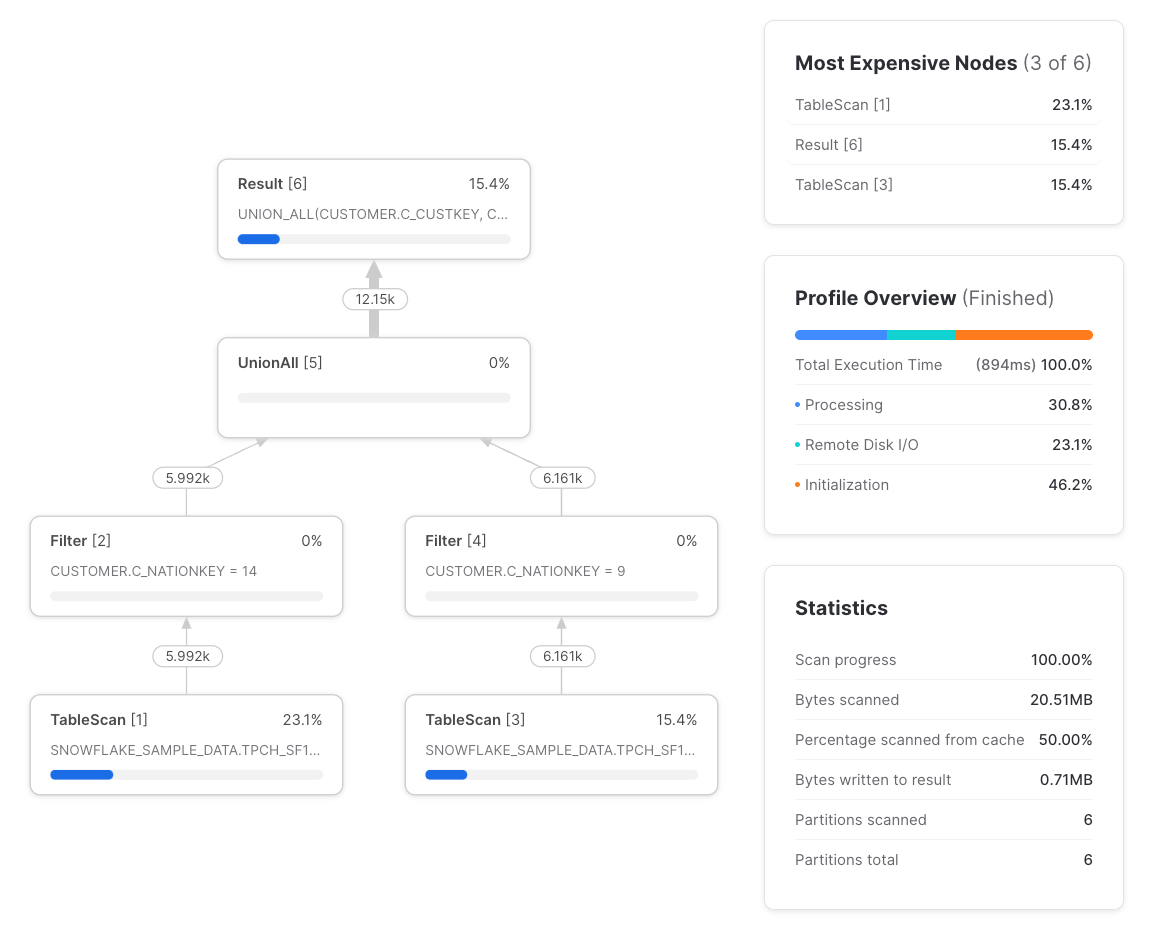
The differences are:
- Two
TableScans instead of one. TheTableScanon the left performs the read from remote storage, and theTableScanon the right uses the local warehouse-cached result of the one on the left. While there are twoTableScans, only one of them performs any remote data fetching. - Two
Filters instead of three, though where a filter is applied after aTableScan, theTableScannode itself takes care of the filtering, which is why the input and output row counts of the filter are the same. - No
WithClauseorWithReferencenodes.
Now we understand how CTEs are translated into an execution plan, let's explore the performance implications.
Sometimes, it’s faster to repeat logic than re-use a CTE
Most of the time, Snowflake’s strategy of computing a CTE's result once and distributing the results downstream is the most performant strategy. But in some circumstances, the cost of buffering and distributing the CTE result to downstream nodes exceeds that of recomputing it, especially as the TableScan nodes use cached results anyway.
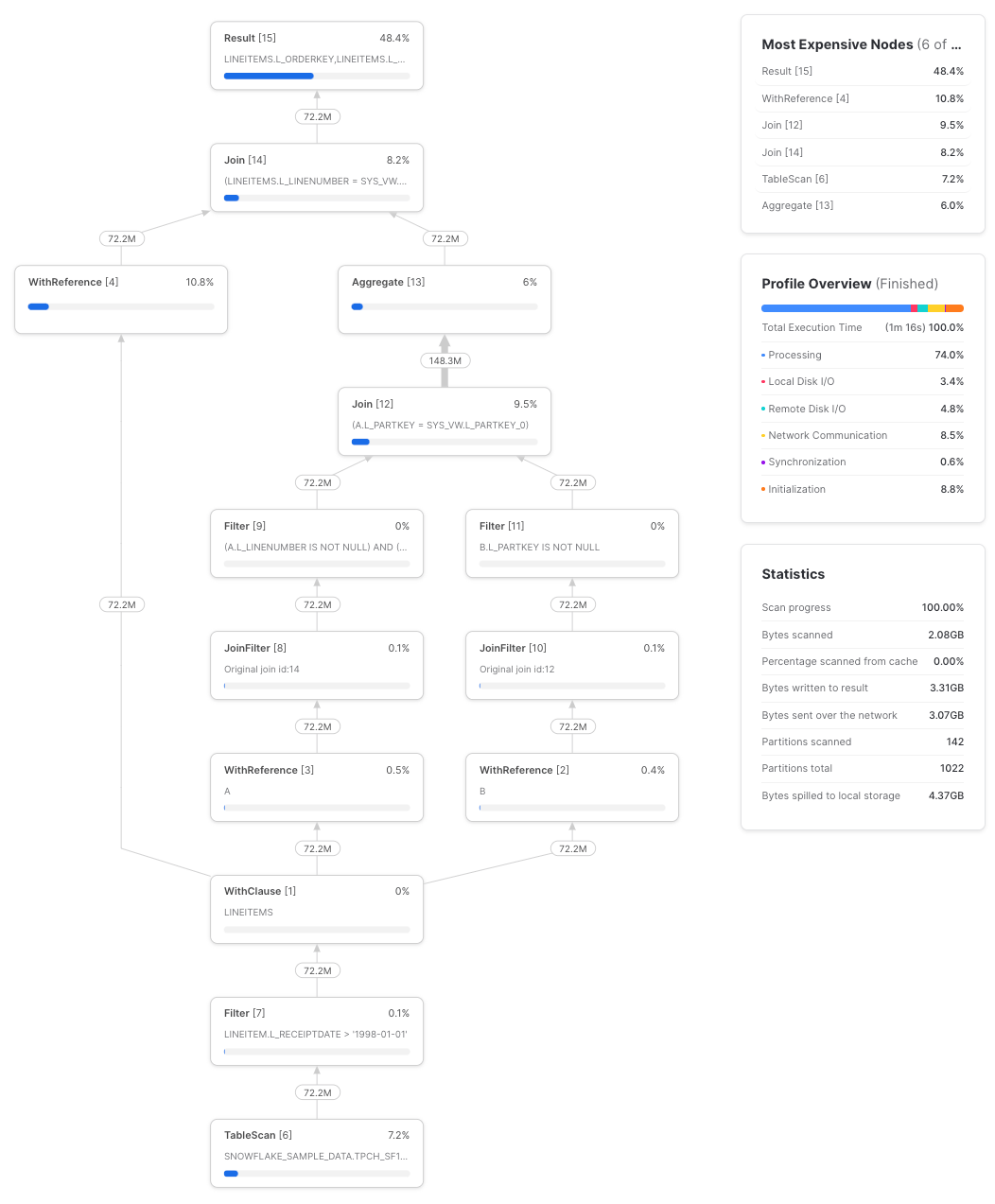
Here’s a contrived example, referencing the lineitems CTE three times:
Across three runs, this query took an average of 1m 17s to complete on a small warehouse. Here’s an example profile:
If we instead re-write the query to repeat the lineitems CTE as a subquery:
The query takes an average of 1m 7s across three runs, a roughly 10% speed improvement. Query profile:

lineitems is a simple CTE. When a CTE reaches a certain level of complexity, it’s going to be cheaper to calculate the CTE once and then pass its results along to downstream references rather than re-compute it multiple times. This behavior isn’t consistent though (as we saw with the basic example in Are CTEs pass-throughs), so it’s best to experiment. Here’s a way to visualize the relationship:
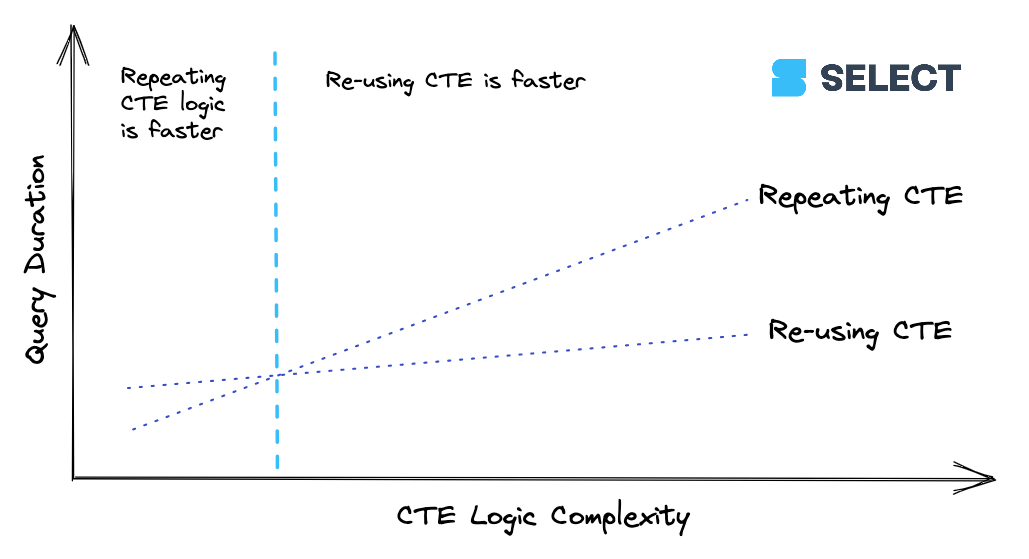
Recommendation
CTEs can be used with confidence in Snowflake, and a CTE that’s referenced only once will never impact performance. Aside from some very specific examples like the above, computing the CTE once and re-using it will yield the best performance vs repeating the CTEs logic. In the previous section, we’ve seen that Snowflake will intelligently push down filters into CTEs to avoid unnecessary full table scans.
If, however, you’re working on optimizing a specific query where performance and cost efficiency are paramount and it’s worth spending time on, experiment by repeating the CTE’s logic. The CTE’s logic can either be repeated in multiple subqueries, or it can be defined in a view and referenced multiple times like the CTE was.
In some scenarios, CTEs prevent column pruning
In previous posts, we covered the unique design of Snowflake’s micro-partitions and how they enable a powerful optimization called micro-partition pruning. Due to their columnar storage format, they also enable column pruning. This is important because it means that only the columns selected in a query need to be retrieved over the network.
Column pruning always works when a CTE is referenced once (when CTEs are referenced only once they are treated as if they don’t exist). In a simple case:
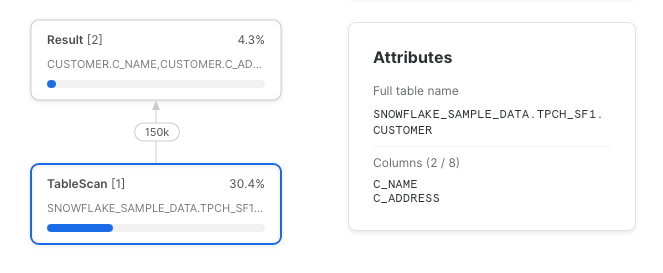
We can see that only the two columns that were selected were read from the underlying table. But as we know from before, a CTE which is referenced only once is a pass-through, and is compiled into a query plan agnostic of its existence.
Column pruning stops working when a CTE is referenced more than once
This time, let’s reference the CTE twice, selecting a single column in each CTE reference.
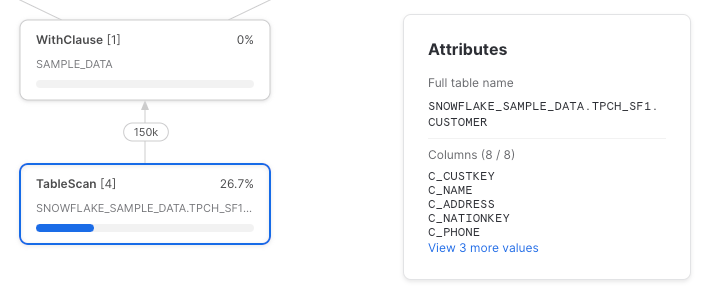
Snowflake unfortunately has not pushed down the column references to the underlying table scan. Here’s the full query profile:
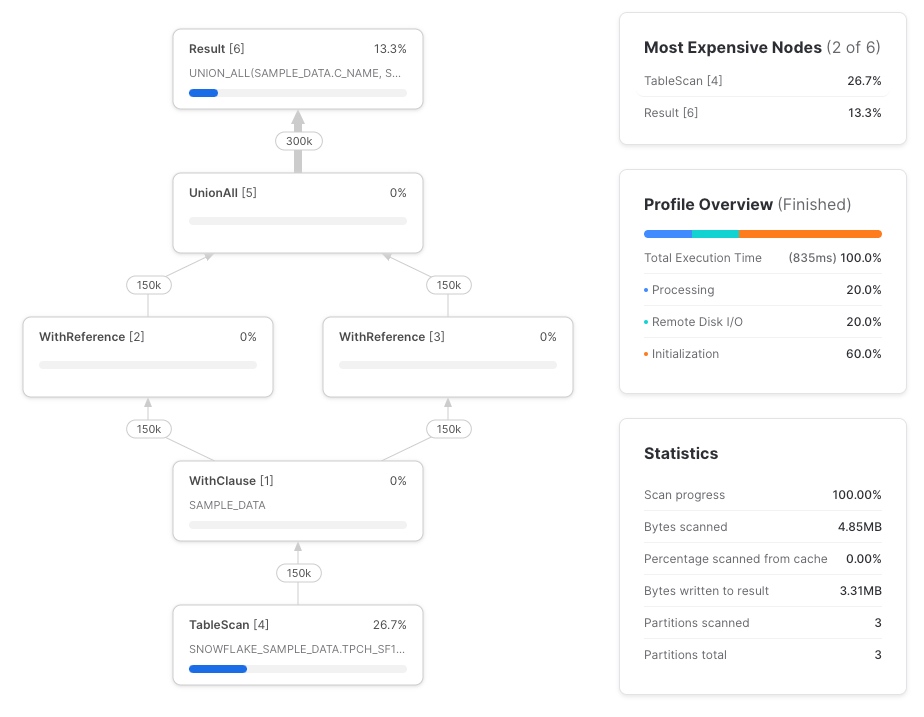
Let’s try it again, this time using direct table references.
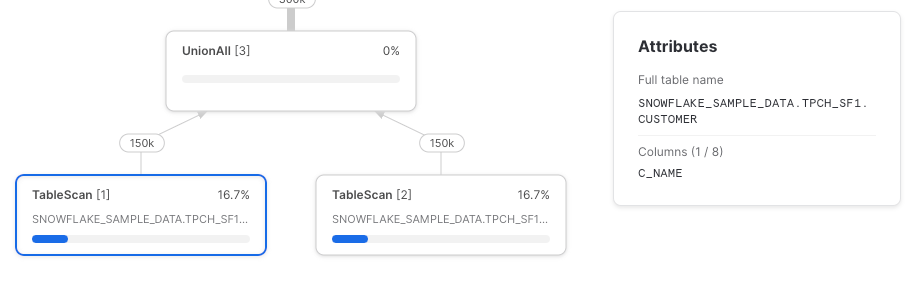
As expected, we have two TableScan nodes and each retrieves only the referenced columns.
Column pruning breaks down with wildcards and joins
Another place where Snowflake may not perform column pruning push-down is with joins (thanks to Paul Vernon for noticing this one). The TableScan of the nation table should ideally only retrieve the n_nationkey and n_name columns, but instead retrieves them all.
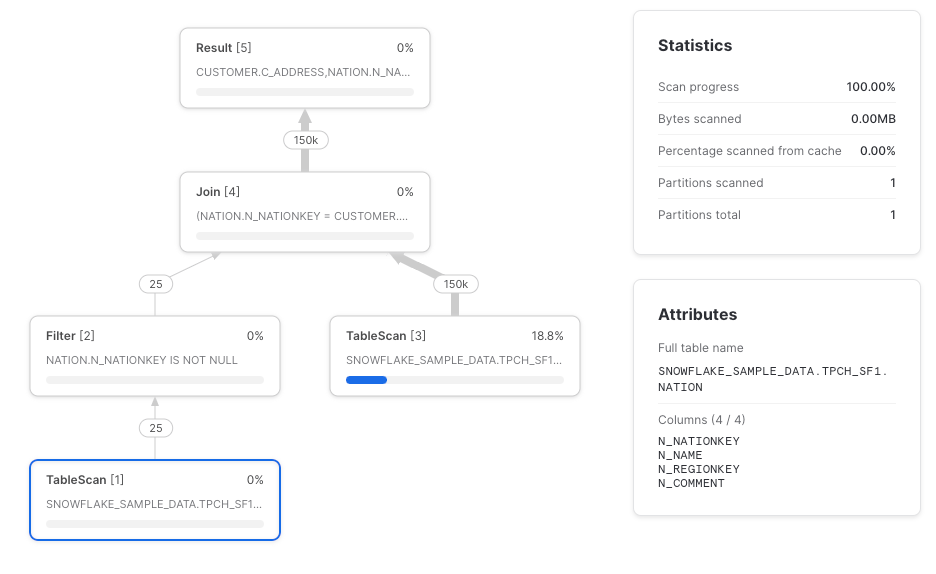
Recommendation
We recommend that column references are listed explicitly where CTEs are used to ensure that TableScans retrieve only the required columns. Though, if a query runs fast enough, the maintenance trade-off of listing out the columns explicitly might not be worth it.
Correspondingly, we recommend against the select * from table CTEs used in dbt's style guide. Instead, reference the needed table directly to ensure column pruning.
So, should you use CTEs in Snowflake?
For almost all cases, yes. If your query runs fast enough and there aren’t cost concerns, go ahead. It’s important not to optimize unnecessarily, as the time and opportunity cost taken to do so can outweigh the benefits.
If you’re working on optimizing a particular query that uses CTEs though, check the following:
- Is a simple CTE referenced more than once? If a CTE doesn’t perform much work, then the overhead of
WithClauseandWithReferencenodes may exceed simply repeating the CTE's calculation using either subqueries or a view. - Are column references being pushed down and pruned as expected in
TableScannodes? If not, try listing out the required columns as early in the query as possible. This may improve the speed of theTableScannode considerably for wide tables.
Identifying and actioning optimization opportunities is time-consuming. SELECT makes it easy, automatically surfacing optimizations like those in this post. Get automated savings from day 1, quickly identify cost centers and optimize your Snowflake workloads. Get access today or book a demo using the links below.

Niall is the Co-Founder & CTO of SELECT, a SaaS Snowflake cost management and optimization platform. Prior to starting SELECT, Niall was a data engineer at Brooklyn Data Company and several startups. As an open-source enthusiast, he's also a maintainer of SQLFluff, and creator of three dbt packages: dbt_artifacts, dbt_snowflake_monitoring and dbt_query_tags.
Want to hear about our latest data cloud learnings?Subscribe to get notified.
Get up and running in less than 15 minutes
Connect your Snowflake, Databricks, or BigQuery account and instantly understand your savings potential.

