

Choosing the right warehouse size in Snowflake
Niall WoodwardSunday, November 27, 2022
Snowflake users enjoy a lot of flexibility when it comes to compute configuration. In this post we cover the implications of virtual warehouse sizing on query speeds, and share some techniques to determine the right one.
The days of complex and slow cluster resizing are behind us; Snowflake makes it possible to spin up a new virtual warehouse or resize an existing one in a matter of seconds. The implications of this are:
- Significantly reduced compute idling (auto-suspend and scale-in for multi-cluster warehouses)
- Better matching of compute power to workloads (ease of provisioning, de-provisioning and modifying warehouses)
Being able to easily allocate workloads to different warehouse configurations means faster query run times, improved spend efficiency, and a better user experience for data teams and their stakeholders. That leads to the question:
Which warehouse size should I use?
Before we look to answer that question, let's first understand what a virtual warehouse is, and the impact of size on its available resources and query processing speed.
What is a virtual warehouse in Snowflake?
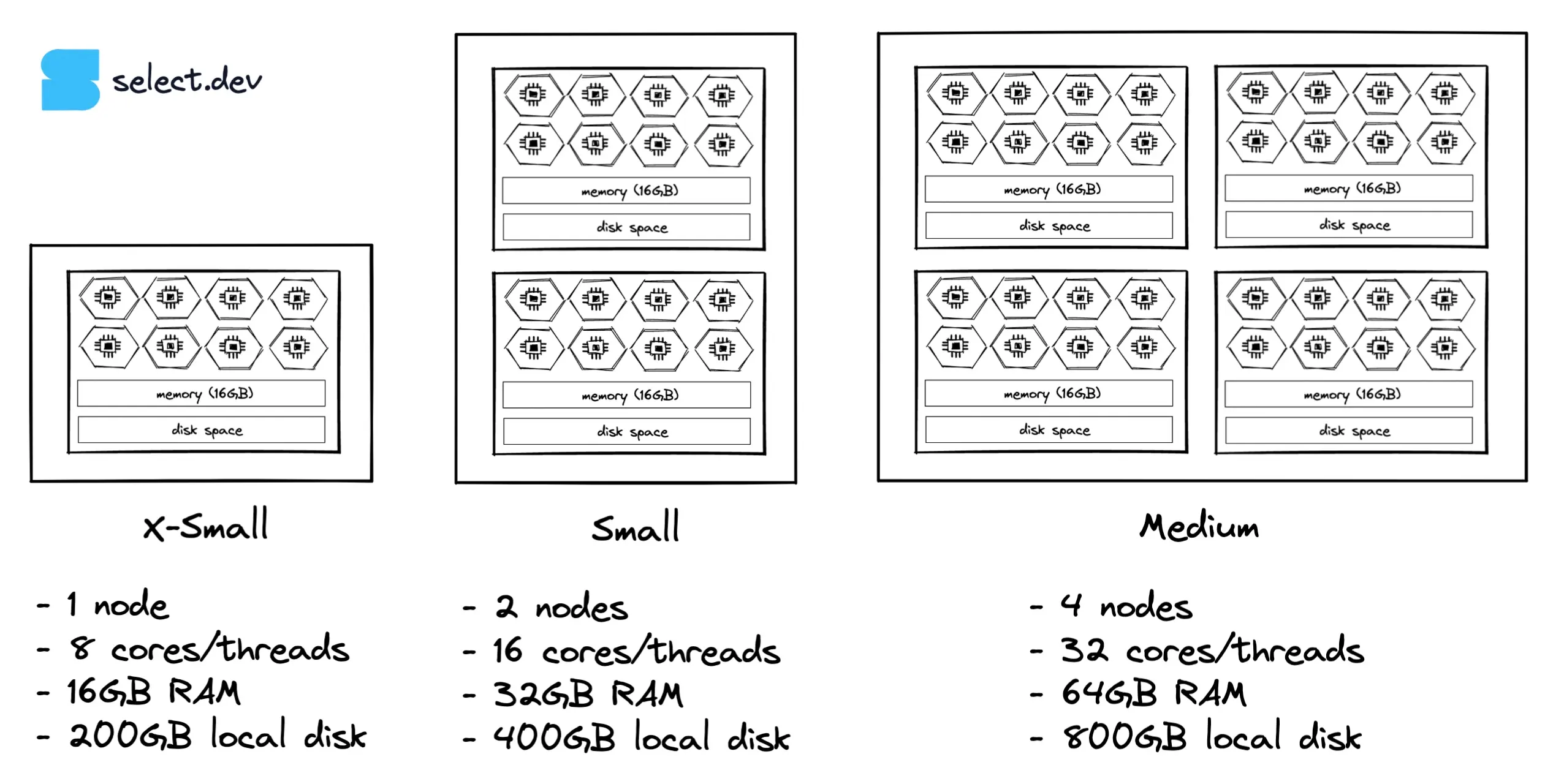
Snowflake constructs warehouses from compute nodes. The X-Small uses a single compute node, a small warehouse uses two nodes, a medium uses four nodes, and so on. Each node has 8 cores/threads, regardless of cloud provider. The specifications aren’t published by Snowflake, but it’s fairly well known that on AWS each node (except for 5XL and 6XL warehouses) is a c5d.2xlarge EC2 instance, with 16GB of RAM and a 200GB SSD. The specifications for different cloud providers vary and have been chosen to provide performance parity across clouds.
While the nodes in each warehouse are physically separated, they operate in harmony, and Snowflake can utilize all the nodes for a single query. Consequently, we can work on the basis that each warehouse size increase doubles the available compute cores, RAM, and disk space available.
What virtual warehouse sizes are available?
Snowflake uses t-shirt sizing names for their warehouses, but unlike t-shirts, each step up indicates a doubling of resources and credit consumption. Sizes range from X-Small to 6X-Large. Most Snowflake users will only ever use the smallest warehouse, the X-Small, as it’s powerful enough for most datasets up to tens of gigabytes, depending on the complexity of the workloads.
| Warehouse Size | Credits / Hour | Snowpark-Optimized Credits / Hour |
|---|---|---|
| X-Small | 1 | N/A |
| Small | 2 | N/A |
| Medium | 4 | 6 |
| Large | 8 | 12 |
| X-Large | 16 | 24 |
| 2X-Large | 32 | 48 |
| 3X-Large | 64 | 96 |
| 4X-Large | 128 | 192 |
| 5X-Large | 256 | 384 |
| 6X-Large | 512 | 768 |
The impact of warehouse size on Snowflake query speeds
1. Processing power
Snowflake uses parallel processing to execute a query across multiple cores wherever it is faster to do so. More cores means more processing power, which is why queries often run faster on larger warehouses.
There’s an overhead to distributing a query across multiple cores and then combining the result set at the end though, which means that for a certain size of data, it can be slower to run a query across more cores. When that happens, Snowflake won’t distribute a query across any more cores, and increasing a warehouse size won’t yield speed improvements.
Unfortunately, Snowflake doesn’t provide data on compute core utilization. The only factor that can be used is the number of micro-partitions scanned by a query. Each micro-partition can be retrieved by an individual core. If a query scans a smaller number of micro-partitions than there are cores in the warehouse, the warehouse will be under-utilized for the table scan step. Snowflake solutions architects often recommend choosing a warehouse size such that for each core there are roughly four micro-partitions scanned. The number of scanned micro-partitions can be seen in the query profile, or query_history view and table functions.
2. RAM and local storage
Data processing requires a place to store intermediate data sets. Beyond the CPU caches, RAM is the fastest place to store and retrieve data. Once it’s used up, Snowflake will start using SSD local storage to persist data between query execution steps. This behaviour is called ‘spillage to local storage’ - local storage is still fast to access, but not as fast as RAM. If Snowflake runs out of local storage, then remote storage will be used. Remote storage means the object store for the cloud provider, so S3 for AWS. Remote storage is considerably slower to access than local storage, but it is infinite, which means Snowflake will never abort a query due to out of memory errors. Spillage to remote storage is the clearest indicator that a warehouse is undersized, and increasing the warehouse size may improve the query’s speed by more than double. Both local and remote spillage volumes can again be seen in the query profile, or query_history view and table functions.
Cost vs performance
CPU-bound queries will double in speed as the warehouse size increases, up until the point at which they no longer fully utilize the warehouse’s resources. Ignoring warehouse idle times from auto-suspend thresholds, a query which runs twice as fast on a medium than a small warehouse will cost the same amount to run, as cost = duration x credit usage rate. The below graph illustrates this behaviour, showing that at a certain point, the execution time for bigger warehouses remains the same while the cost increases. So, how do we find that sweet spot of maximum performance for the lowest cost?
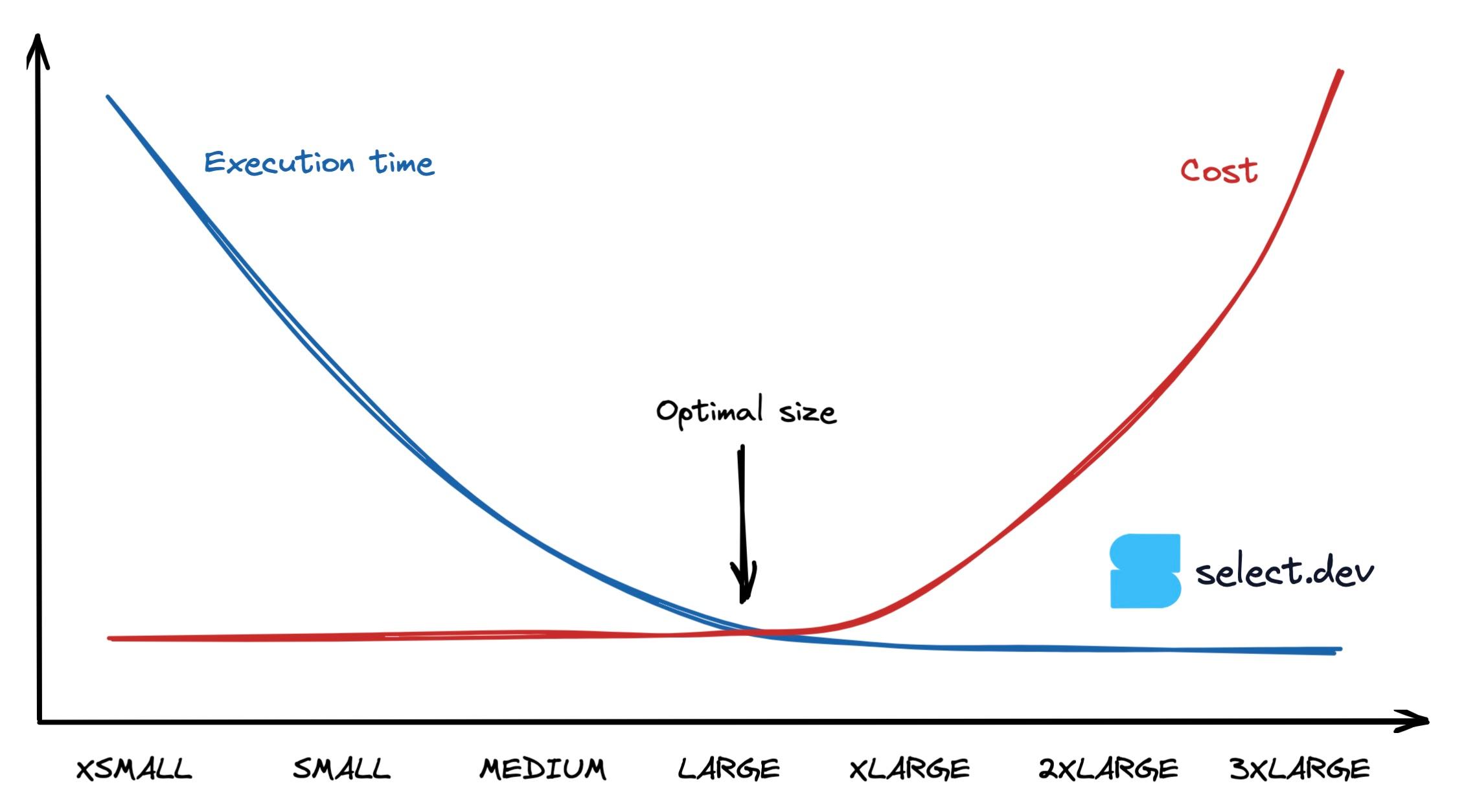
Determining the best warehouse size for a Snowflake query
Here’s the process we recommend:
- Always start with an X-Small.
- Increase the warehouse size until the query duration stops halving. When this happens, the warehouse is no longer fully utilized.
- For the best cost-to-performance ratio, choose a warehouse size one smaller. For example, if going from a Medium to a Large warehouse only decreases the query time by 25%, then use the medium warehouse. If faster performance is needed, use a larger warehouse, but beware that returns are diminishing at this point.
A warehouse can run more than one query at a time, so where possible keep warehouses fully loaded and even with light queueing for maximum efficiency. Warehouses for non-user queries such as transformation pipelines can often be run at greater efficiency due to the tolerance for queueing.
Heuristics to identify incorrectly sized warehouses
Experimentation is the only way to exactly determine the best warehouse size, but here are a few indicators we’ve learned from experience:
Is there remote disk spillage?
A query with significant remote disk spillage typically will at least double in speed when the warehouse size increases. Remote disk spillage is very time-consuming, and removing it by providing more RAM and local storage for the query will give a big speed boost while saving money if the query runs in less than half the time.
Is there local disk spillage?
Local disk spillage is nowhere near as bad as remote disk spillage, but it still slows queries down. Increasing warehouse size will speed up the query, but it’s less likely to double its speed unless the query is also CPU bound. It’s worth a try though!
Does the query run in less than 10 seconds?
The query is likely not fully utilizing the warehouse’s resources, which means it can be run on a smaller warehouse more cost-effectively.
Example views for identifying oversized warehouses
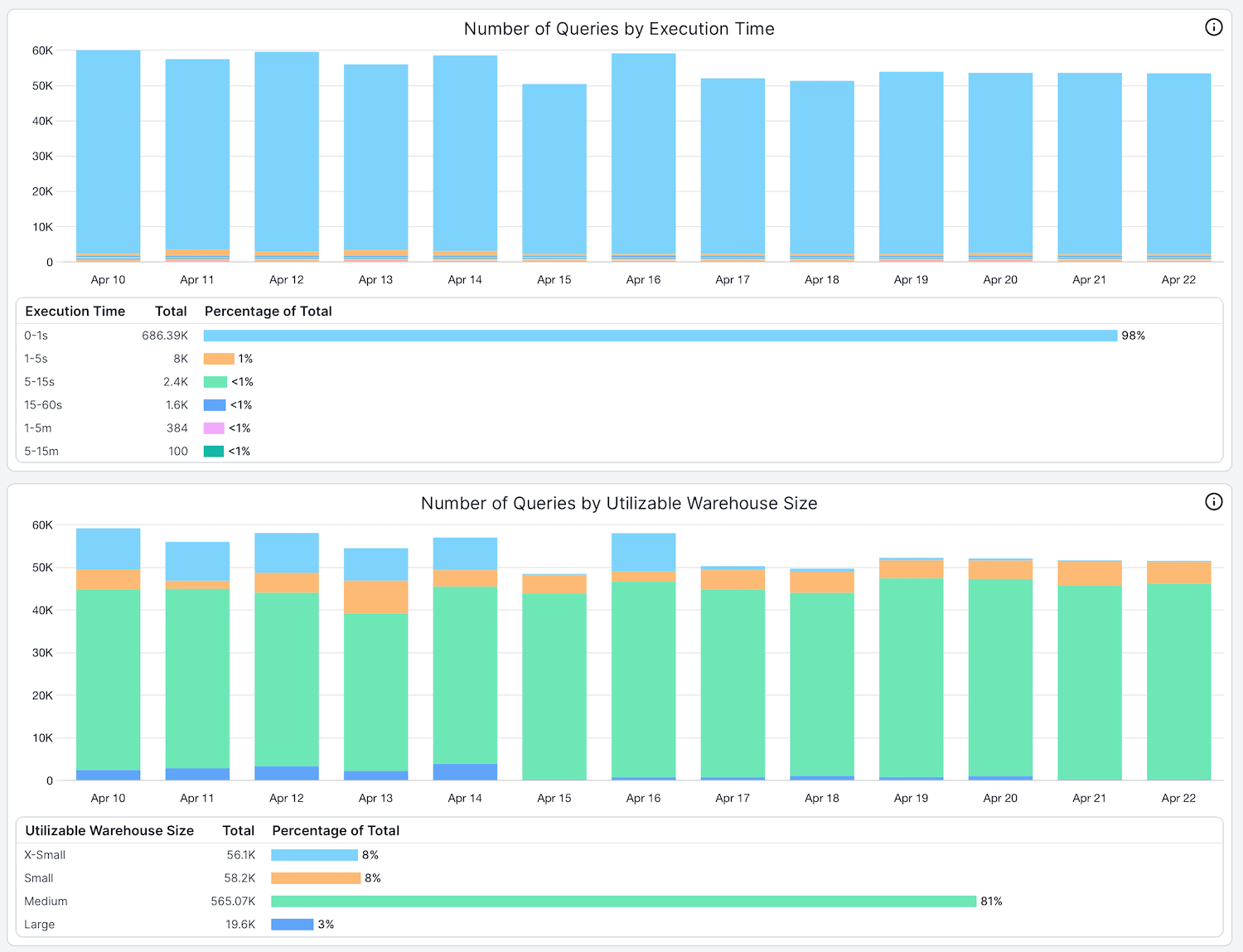
Here's two helpful views we leverage in the SELECT product to help customers with warehouse sizing:
- The number of queries by execution time. Here you can see that over 98% of the queries running on this warehouse are taking less than 1 second to execute.
- The number of queries by utilizable warehouse size. Utilizable warehouse size represents the size of warehouse a query can fully utilize. Where lots of queries don't utilize the warehouse's size, it indicates that the warehouse is oversized or the queries should run on a smaller warehouse. In this example, over 96% of queries being run on the warehouse aren’t using all 8 nodes available in the Large warehouse.
Using partitions scanned as a heuristic
Another helpful heuristic is to look at how many micro-partitions a query is scanning, and then choose the warehouse size based on that. This strategy comes from Scott Redding, a resident solutions architect at Snowflake.
The intuition behind this strategy is that the number of threads available for processing doubles with each warehouse size increase, and each thread can process a single micro-partition at a time. You want to ensure that each thread has plenty of work available (files to process) throughout the query execution.
To interpret this chart, this goal is to aim for 250 micro-partitions per thread. If your query needs to scan 2000 micro-partitions, then running the query on an X-Small will give each thread 250 micro-partitions (files) to process, which is ideal. Compare this with running the query on a 3XL warehouse, which has 512 threads. Each of these threads will only get 4 micro-partitions to process, which will likely result in many threads sitting unused.
The main pitfall with this approach is that while micro-partitions scanned is a significant factor in the query execution, other factors like query complexity, exploding joins, and volume of data sorted will also impact the required processing power.
Closing
Snowflake makes it easy to match workloads to warehouse configurations, and we’ve seen queries more than double in speed while costing less money by choosing the correct warehouse size. Increasing warehouse size isn't the only option available to make a query run faster though, and many queries can be made to run more efficiently by identifying and resolving their bottlenecks. We'll provide a detailed guide on query optimization in a future post, but if you haven't yet, check out our previous post on clustering.
If you’re interested in being notified when release future posts, subscribe to our mailing list below.

Niall is the Co-Founder & CTO of SELECT, a SaaS Snowflake cost management and optimization platform. Prior to starting SELECT, Niall was a data engineer at Brooklyn Data Company and several startups. As an open-source enthusiast, he's also a maintainer of SQLFluff, and creator of three dbt packages: dbt_artifacts, dbt_snowflake_monitoring and dbt_query_tags.
Want to hear about our latest data cloud learnings?Subscribe to get notified.
Get up and running in less than 15 minutes
Connect your Snowflake, Databricks, or BigQuery account and instantly understand your savings potential.

