

What are custom workloads?
SELECT supports custom workloads for Snowflake and BigQuery, but currently not for Databricks.
Many users leverage their database for unique workloads, such as custom ETL pipelines, machine learning applications, or analytics applications. Users need to monitor these workloads to understand their cost and performance over time. By adding query comments or query tags to the queries run by these workloads, SELECT users can benefit from enhanced monitoring capabilities compared to the default Query Patterns workload type.
Feature Overview
The SELECT custom workload integration allows you to better understand and optimize spend associated with these unique workloads.
- Quickly identify expensive workloads by name or application (instead of by Query Pattern), and understand how their cost and performance vary over time
- Easily dissect your database spend across a variety of different dimensions such as environment, team and tenant_id
- Drill into the execution history of any workload and view query profile diagnostics for each run
- Receive tailored optimization recommendations to improve workload cost and performance
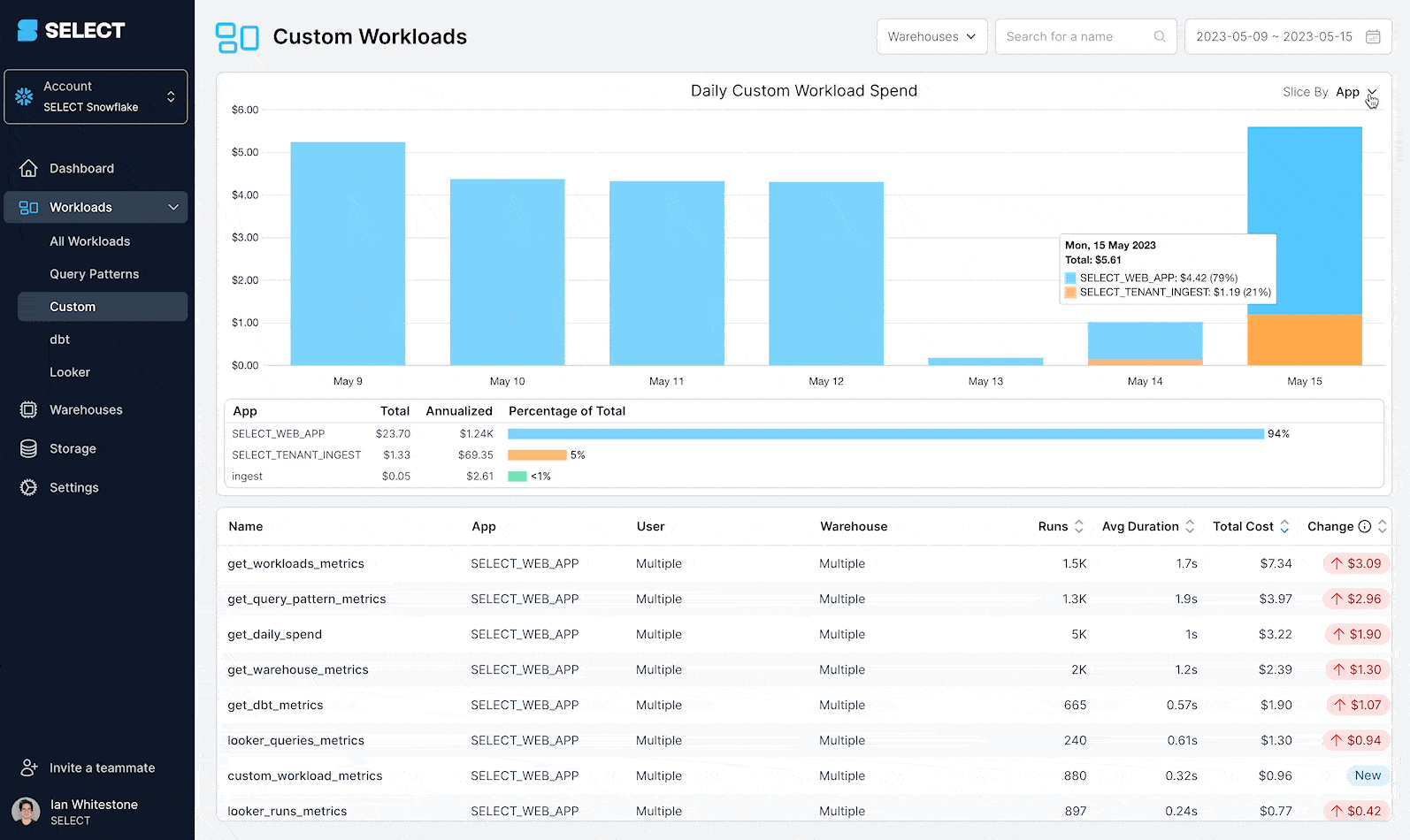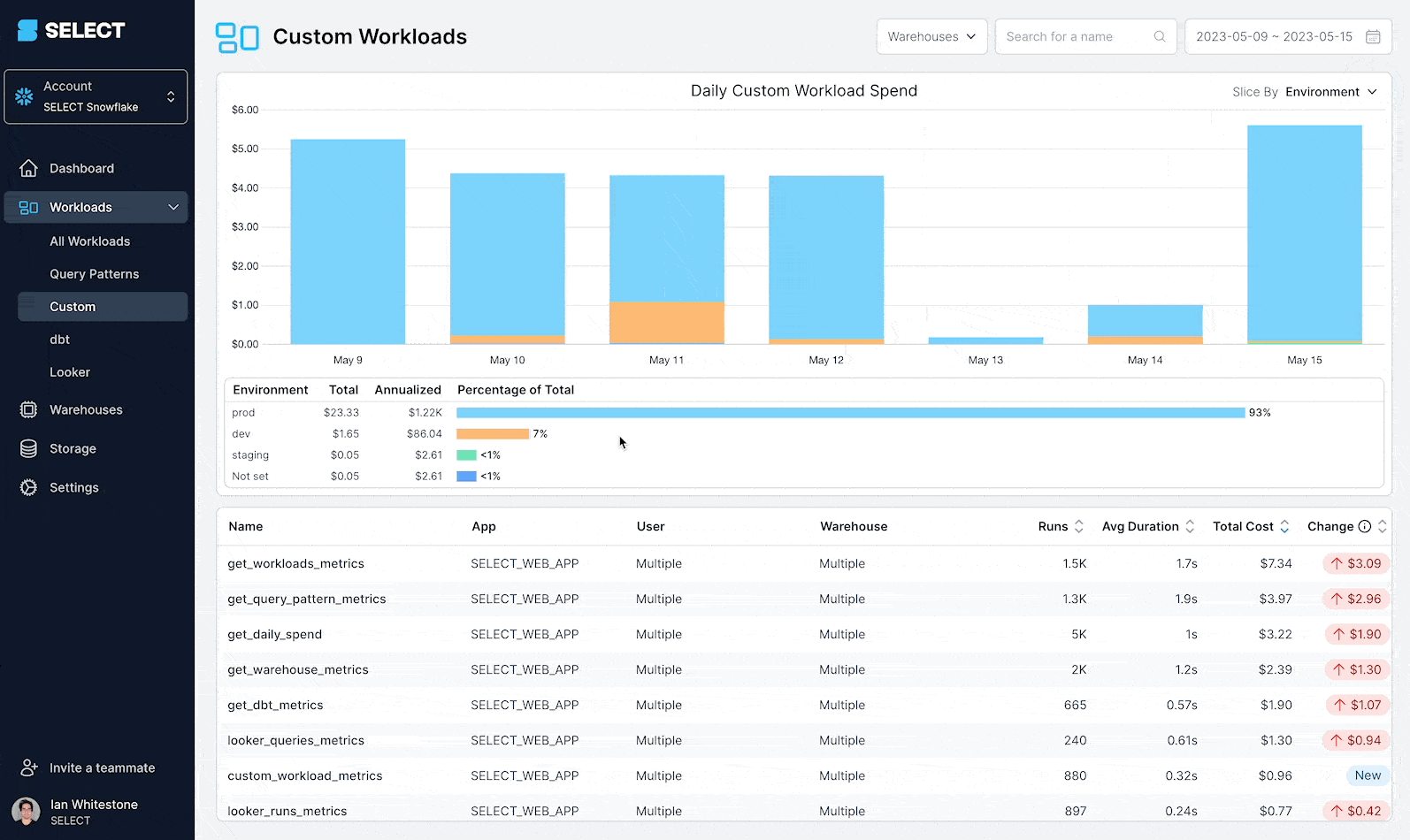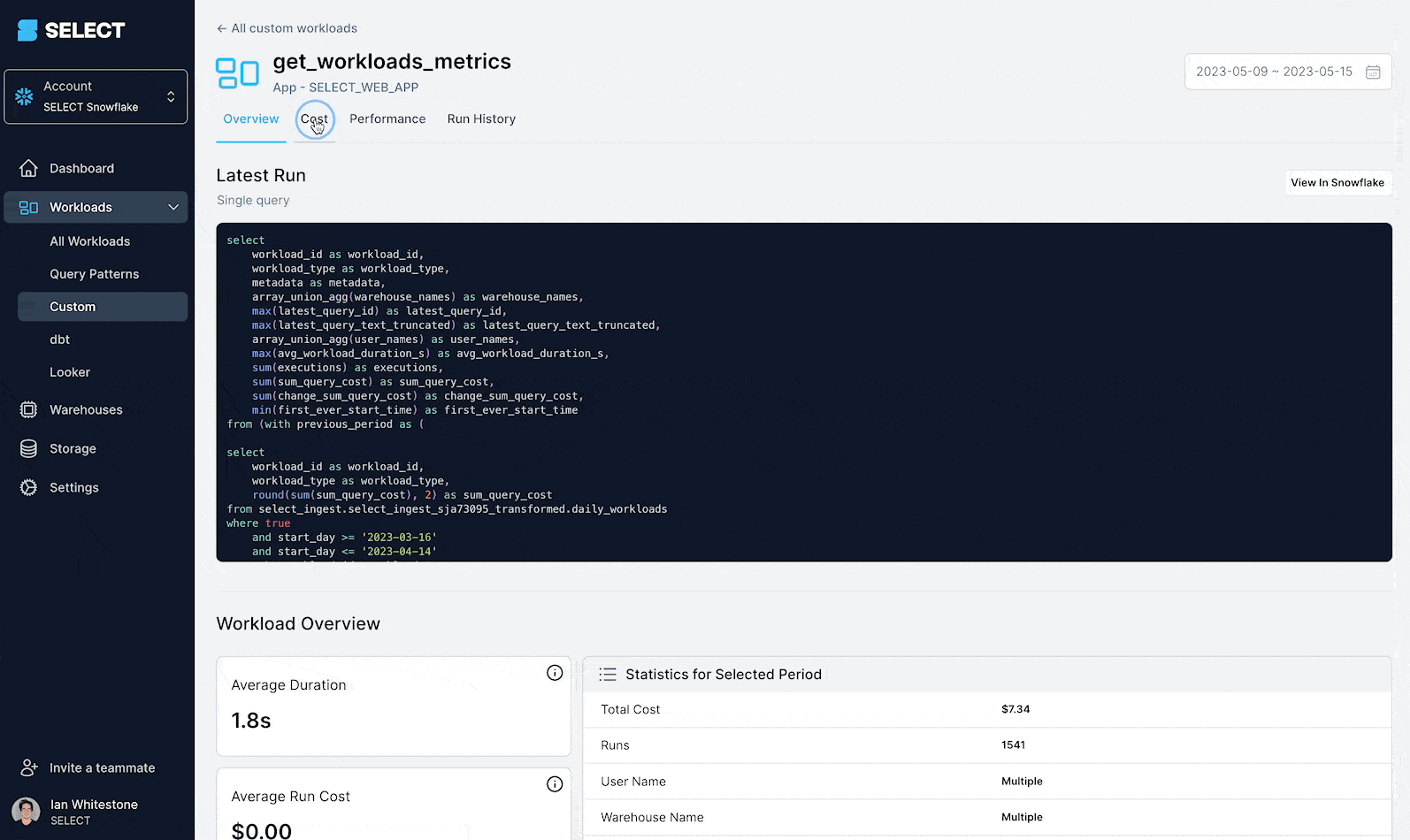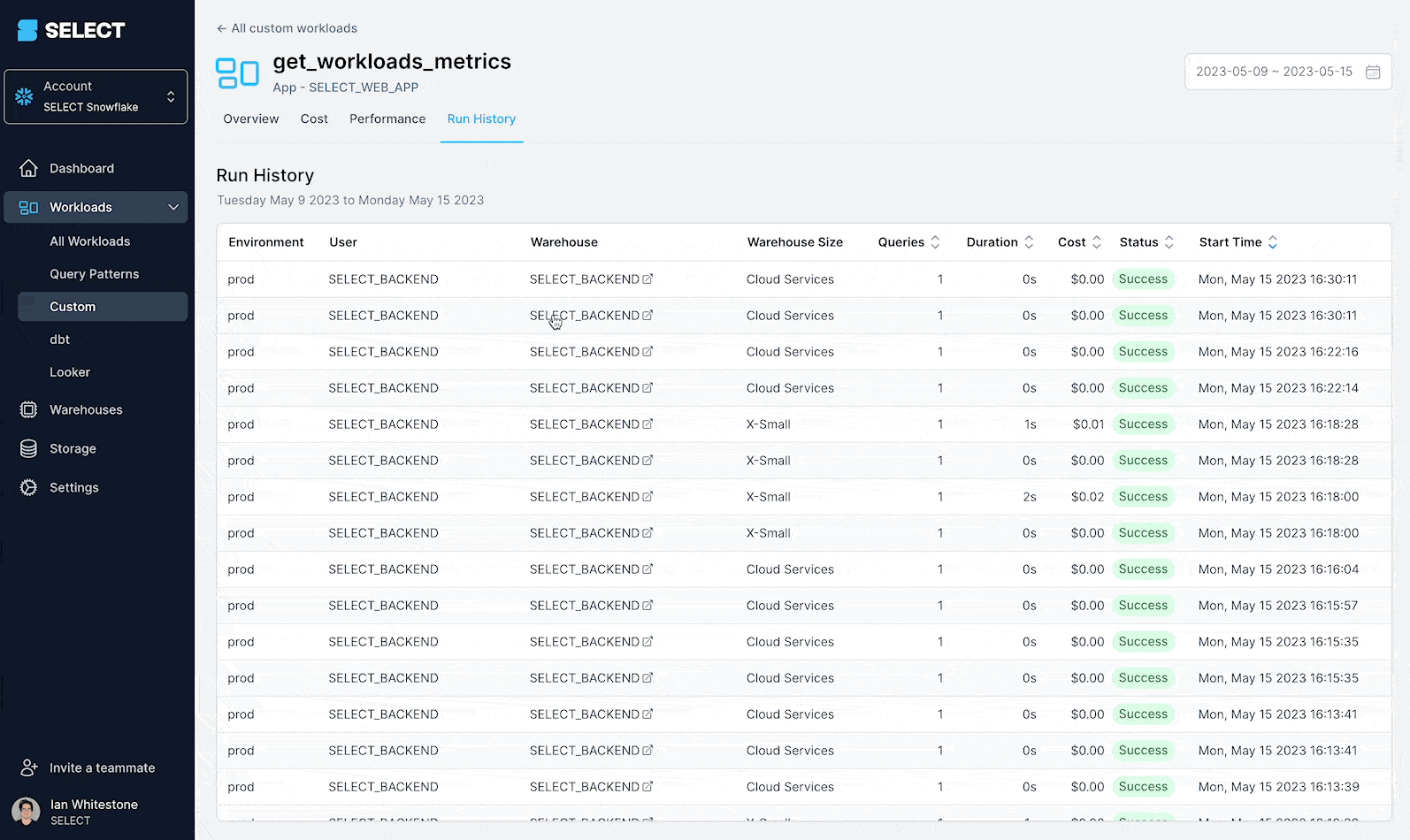
The Custom Workloads feature works by adding metadata to your queries via SQL comments, Snowflake query tags or BigQuery job labels. SELECT will automatically detect this metadata and intuitively surface these workloads in the UI:
By default, SELECT categorizes compute spend into Query Patterns based on the SQL fingerprint of the query. When users make significant changes to the structure of the SQL (add new fields, filter conditions, or join in new datasets), that SQL will become part of a new Query Pattern. This makes it more difficult to understand the impact of these changes on cost and performance, as you'll have to compare two different query patterns.
With custom workloads, queries are grouped into a workload based on the query tag or comment. No matter what changes are made to the SQL, the queries will consistently be associated with the same workload specified in the query metadata, allowing you to confidently assess the impact of any changes made.
Integrating with custom workloads
To support custom workload monitoring (i.e. queries run by custom tooling), SELECT utilizes query metadata. The query metadata is a JSON object, and can be set in either the query's tag or in a comment. The schema is as follows:
Example query comments
Both multi-line and single-line comment syntax are supported. If using single-line comments, ensure that the final character in the comment is a closing curly brace and not a semi-colon.
Multi-line comment
Single-line comment:
Your SQL statement must not have a semicolon before the query comment, or else the comment will not be sent to Snowflake:
Example query tag
Alternatively, in Snowflake, query tags can be used. The downside to using query tags is the need to both set and unset the query tag in the session, adding latency and additional complexity.
Example BigQuery label
Alternatively, in BigQuery, job labels can be used. There is no set and unset concern like in Snowflake.
Example Python implementation using query comments
Here's an example implementation using the Snowflake Python Connector:
How query metadata is reflected in the SELECT UI
app and workload_id
The most important fields to set in the query comment/tag metadata are the app and workload_id. By default, they will show up in the UI in the main table as shown below.
The example query below would be associated with the first row shown in the table above, regardless of which user or warehouse it ran on.
When to use run_id
Sometimes a single workload will have multiple steps associated with it. For example, a data transformation workload may run 3 queries everytime it runs:
- A query to create a temporary table
- A query to merge data from the temporary table into the main table
- A final query to delete the temporary table
To help track workloads like this, SELECT's custom workloads feature has first class support for a field called run_id. An example workload is shown below which issues 3 queries each time it runs. Notice how each query has the same unique run_id associated with it. The run_id can be anything, it just needs to be unique to each run. The example below uses Python's uuid module (str(uuid.uuid4())).
In the SELECT custom workloads UI, you'll be able to see all queries associated with each workload run, and track run duration and cost over time (as opposed to individual query duration and cost over time).
Additional Metadata
When coming up with your tagging structure, think about logical ways you may want to analyze your workloads. For example, if your pipeline has a retry mechanism built-in, you may want to add a is_retry field to your metadata so you can analyze how much retries are costing you across all workloads.
Other helpful examples of fields you may want to add could include:
tenant_id: i.e. 'customer_a', 'customer_b'environment: i.e. 'dev', 'staging', 'prod', etc.department: i.e. 'advanced analytics', 'support', 'core', etc.team: i.e. 'data_engineering', 'analytics_engineering', 'solutions_architecture', etc.owner_email: i.e. '[email protected]'domain: i.e. 'marketing', 'growth'
All of these fields can be exposed as filters in the SELECT UI, allowing you to slice and dice accordingly. Consider a workload which has a query metadata field called runner, which tracks the source system that emitted the query. You can see cost and performance data split by the runner metadata field directly in the UI:
See the section below on "Leveraging custom metadata fields" for more information.
Leveraging custom metadata fields
Custom workloads allow users to tag their queries with comments or Snowflake query tags. Here’s an example query comment SELECT has for one of its custom workloads:
Custom workload fields like app, workload_id and environment are already available for filtering & slicing in the UI out of the box. To enable the same behaviour for other fields you specify in your custom workload query comment/tag, head to Settings → Custom and specify the keys you want enabled.
Once added, you can filter and slice by this metadata throughout the UI!
Looking to do cost chargebacks or showbacks using the metadata you've added to your query? You can now flexibly allocate costs based on custom workload metadata using SELECT's Usage Groups feature!
We currently do not support filtering/slicing on custom meta keys which contain complex data types like arrays or objects. If this is a requirement for you, please let us know and we will add this functionality.
Note, you can still add this data to your query comment/tag and perform you own analysis on it. You just want be able to interact with that data in the SELECT UI as of today.

