

A Beginner's Guide to Snowpark Container Services: Understanding the Building Blocks and Pricing
Jeff SkoldbergSaturday, November 15, 2025
If you're coming to Snowpark Container Services (SPCS) from a background in traditional cloud platforms like AWS, GCP, or Azure, Snowpark Container Services might feel familiar yet confusingly different. You can run containers, but the terminology (compute pool, service, etc.) and behavior are just foreign enough to be confusing. Let's break it down.
What is Snowpark Container Services?
Snowpark Container Services lets you run containerized applications directly inside Snowflake. It is Snowflake's version of AWS ECS, Google Cloud Run, or Azure Container Instances. But instead of running in your cloud account, your containers run in Snowflake's compute environment and have native access to your Snowflake data.
The best part is your containers can directly query Snowflake tables, call Snowflake functions, and access your data without the need to create a service account, managing credentials for data access, or moving data outside the platform. Also the users of your app will be granted access using a simple grant statement, so you don’t need to build authentication software or manage user / passwords, etc. I recently deployed a container app for an AWS / Snowflake customer, and they chose SPCS instead of ECS because the user management and security is much simpler.
There are lots of articles covering examples of how to deploy apps in Snowpark Container Services. In this article, we’ll focus mostly on the building blocks (terminology), pricing, and some of the nuances or difference vs traditional container services.
The Core Building Blocks
Let's understand the four main objects you'll work with:
1. Image Repository
This is Snowflake's container registry, similar to Docker Hub or Amazon ECR. You push your Docker images here, and Snowflake pulls from it when starting your services.
Snowpark Container Services does not pull container images directly from external registries like Docker Hub. You can use public base images when building locally, but before deploying to Snowflake, you must push the final image to a Snowflake image repository within your account. Services can only run images stored in Snowflake’s own repository system.
2. Compute Pool
Here's where things diverge from what you might know. A compute pool is a collection of virtual machine instances that run one or many containers. Think of it as your cluster of nodes that can run many services or apps.
Key parameters:
MIN_NODES/MAX_NODES: How many VM instances can run (this is your capacity, not your containers). Min nodes must be greater than zero. It will auto-suspend if no services are running.INSTANCE_FAMILY: The size/type of VM (CPU_X64_S, CPU_X64_M, GPU_NV_S, etc.)AUTO_RESUME: Whether the pool automatically starts when neededAUTO_SUSPEND_SECS: How long to wait before suspending an idle pool with no services running.
3. Service
A service is the running containerized application. It defines which image to run, how many instances (containers) to start, and how to route traffic to them.
The service reads a YAML specification file (stored in a stage) that describes your containers, similar to a Kubernetes deployment or Docker Compose file. Here’s an example SPECIFICATION_FILE.yml that the service will read on startup:
4. External Access Integration (Optional)
If your container needs to call external APIs or services outside Snowflake, you need an external access integration. This is Snowflake's way of controlling outbound network access.
As you can see, there are some new concepts here that are very specific to this service. General Snowflake knowledge or cloud knowledge will help jump start you, but you need to get these new terms under your belt.
How much does Snowpark Container Services cost?
The pricing on SPCS is quite reasonable in my opinion. It will be more expensive compared to traditional container services (ECS, Cloud Run, ACI), but the added benefits of Snowflake governance and data proximity may often be worth it. Here are the various charges associated with SPCS.
Compute Pools
The main billing component of SPCS is the compute pools. On the surface, SPCS seems to be very affordable. An Extra Small costs only 0.06 Credits per hour. At $3 per credit, an XS would cost $4.32 per day or $1576 per year. Similar hardware on Cloud Run would cost just under $3 / day. So SPCS is more expensive, but has the added benefits we discussed.
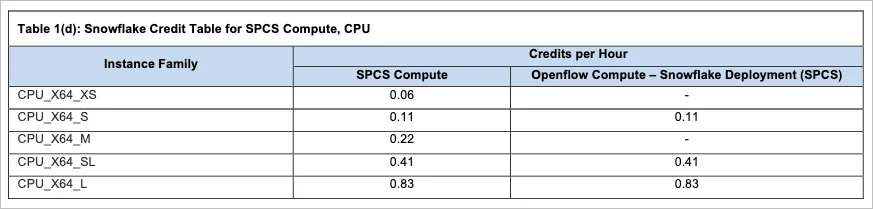
When a compute pool resumes, you are billed for a minimum of 5 minutes.
Comparison to Snowflake Virtual Warehouses costs
Compared to Snowflake’s virtual warehouses, the smallest size warehouse costs 1 credit per hour. SPCS provides a much cheaper alternative for lightweight tasks like running Python scripts or hosting notebooks. As shown above, you can run a compute node for 6% the total cost of an XS virtual warehouse!
Storage Costs
Storage is cheap, and SPCS won’t burn a ton of storage, but let’s be aware of this aspect. Here are the various ways you could be billed for storage:
- Image Repository: this is implemented as a stage, so standard storage rates apply.
- Block volumes for containers: these store your application state, similar to AWS EBS or Google Persistent Disk. This is most expensive aspect when it comes to storage. Ranging from about $82 to $100 per TB per month.
- Logging to Snowflake’s event table (standard storage)
- Any other stage / table used by your app (standard storage)
SPCS Cost Management Gotcha: Public Services Don't Auto-Suspend
Here's where many newcomers (myself included) get surprised. If you're used to Cloud Run, AWS Lambda, ECS, or similar "serverless" container platforms, you might expect your service to automatically shut down when no one is using it. It doesn't.
The Reality of SPCS Costs
Ben Franklin said "Experience is the best teacher, but a fool will learn from no other." Unfortunately I learned from the following the hard way, so hopefully you can learn from my mistakes!
Compute pools have AUTO_SUSPEND_SECS, but it only applies when the pool is empty. If you have a service running on the compute pool, the pool stays active. Setting AUTO_SUSPEND_SECS = 60 on your compute pool doesn't suspend the pool if a service is running and services will not suspend themselves.
Services run 24/7 by default. When you create a service with MIN_INSTANCES = 1, (0 is not allowed), Snowflake keeps one container running constantly. That means you're paying for compute 24/7 until you explicitly suspend the service. Unlike cloud run, it won’t scale to zero when no one is using it. The auto_suspend_secs property of the service is a preview feature; it will work for internal apps that do not have public endpoints such as Service Functions, and Service to Service communications. But for web apps running in containers, they will not auto-suspend when idle. Snowflake only tracks internal service function calls for determining inactivity, not ingress HTTP traffic.
As mentioned above, it is still affordable due to the low credit consumption rate, even if you let things run 24x7. ($4.32 / day assuming $3 / credit and XS). This is just something to look at for as it is came as a surprise to me.
The Two-Step Suspension Dance
For the compute pool to auto-suspend, you must first suspend the service:
Auto-Resume Works (But Only for Services)
Here's the silver lining: While services don't auto-suspend, they do auto-resume when someone accesses their endpoint - but only if you enable it:
Snowpark Container Services Cost Management Strategies
Given these limitations, here are practical approaches if you don’t want your app to run 24x7:
1. Manual Suspend/Resume (Best for Dev/Test)
2. Scheduled Tasks (Good for Predictable Usage)
3. Monitor and Alert (Essential for Production)
Accessing suspended SPCS URLs
When the service is suspended, the user will reach this error when visiting the URL:
As long as the service and compute pool have auto-resume enabled, they will begin to spin up when the user tries the URL. It will take about 39-60 seconds, then they can refresh the page. This experience is a little sub-optimal, but not terrible if the users know to expect it.
Running Batch Jobs using Compute Pools
Since SPCS Compute Pools have a much cheaper cost per credit, we can leverage this as a much cheaper way to run Python (or any language) batch jobs in Snowflake. Let’s say you have a Python job that is containerized and pushed to a Snowflake registry, and a YAML file that describes the service pushed to a Stage. Then you can run an execute job service ... command to run the code in that container. These services will turn off when they are finished, allowing the Compute Pool to auto-suspend normally. This is a nice trick to harness cheaper compute in Snowflake!
Monitoring Snowpark Container Services cost in Snowsight
The Snowsight UI provides a convenient way to monitor SPCS spend. Using accountadmin role or a role with access to monitor usage, navigate to Admin → Cost Management → Consumption then change the Service Type filter to SPCS.
Key Takeaways
- Compute pools don't idle if services are running - The
AUTO_SUSPEND_SECSsetting only applies when the pool has no active services - You must explicitly manage service lifecycle - Use
ALTER SERVICE ... SUSPENDwhen not in use, and enableAUTO_RESUME = TRUEfor automatic wake-up (for http apps) - Auto-suspend doesn't work for public endpoints - Services with public endpoints can auto-resume but won't auto-suspend based on inactivity
- Plan your cost management strategy upfront - Decide whether you'll use manual suspension, scheduled tasks, or just keep services running and budget accordingly
- Every object needs permissions - Image repositories, stages, compute pools, external access integrations, and services all require specific grants
Getting Started Checklist
✅ Create dedicated role for container management
✅ Set up database, schema, image repository, and stage
✅ Configure external access integration if calling external APIs
✅ Create compute pool with appropriate size and auto-suspend settings
✅ Upload service specification to stage
✅ Create service with AUTO_RESUME = TRUE
✅ Document manual suspend procedures or create scheduled tasks
✅ Set up monitoring queries to track running services and costs
✅ Test the suspend/resume cycle before deploying to production
Wrap Up
Snowpark Container Services brings the power of containerized applications directly to your data in Snowflake. But there is a learning curve; you need to understand image repositories, compute pools, services, and their interconnected behavior. Once you grasp these building blocks and the cost management quirks, you can build powerful data applications that run right next to your data without ever leaving the Snowflake platform.

Jeff is a Data and Analytics Consultant with 15+ years experience in automating insights and using data to control business processes. From a technology standpoint, he specializes in Snowflake + dbt + Tableau. From a business topic standpoint, he has experience in Public Utility, Clinical Trials, Publishing, CPG, and Manufacturing. Reach out any time, [email protected].
Want to hear about our latest data cloud learnings?Subscribe to get notified.
Get up and running in less than 15 minutes
Connect your Snowflake, Databricks, or BigQuery account and instantly understand your savings potential.

