

Snowflake Summit 2026: Product Announcement Recap
Jeff SkoldbergThursday, June 11, 2026
Snowflake Summit 2026 was the most announcement-dense Summit in the event's history. But if last year felt like Snowflake was redefining what a data platform could be, this year felt more incremental. The platform is maturing, becoming incredibly broad and complex, the agentic narrative is solidifying, but a lot of what shipped was Snowflake filling in gaps and deepening capabilities it already had, or deepening the AI ecosystem.
Two of the major announcements were less about new code and more about new names. Cortex Code is now Snowflake CoCo, and Snowflake Intelligence is now Snowflake CoWork. Kleinerman was candid about why: everyone was already calling Cortex Code "CoCo" in the hallways, and the scope of Snowflake Intelligence had grown so far beyond a chatbot that "intelligence" undersold it. CoCo is the control plane for builders; CoWork is the control plane for everyone else. Nearly every announcement below ties back to one of those two surfaces, so keep them in mind as we go.
Let's get into everything Snowflake announced. (See dedicated CoCo and CoWork sections at the end).
Data Engineering and Ingestion
Snowflake Datastream - Private Preview
The marquee ingestion announcement. Snowflake Datastream is a fully managed, Kafka-wire-compatible streaming service built directly into Snowflake. In true Snowflake fashion it separates storage and compute, does zero-copy streaming with sub-second latency, and, because it's Kafka wire compatible, all your existing Kafka clients and applications can stream into it directly with little more than a config change. Topics land as governed Snowflake or Iceberg tables, inheriting RBAC, masking, lineage, and Time Travel automatically.
This is a big deal. So many of us have bolted a separate Kafka stack onto Snowflake just to capture events upstream, and now Snowflake wants to absorb that entire layer into the platform. If the latency, exactly-once semantics, and cost hold up at scale, that's one fewer vendor and one fewer place for governance to fracture. Datastream will be in Private Preview shortly.
OpenFlow gets programmable, private, and broader
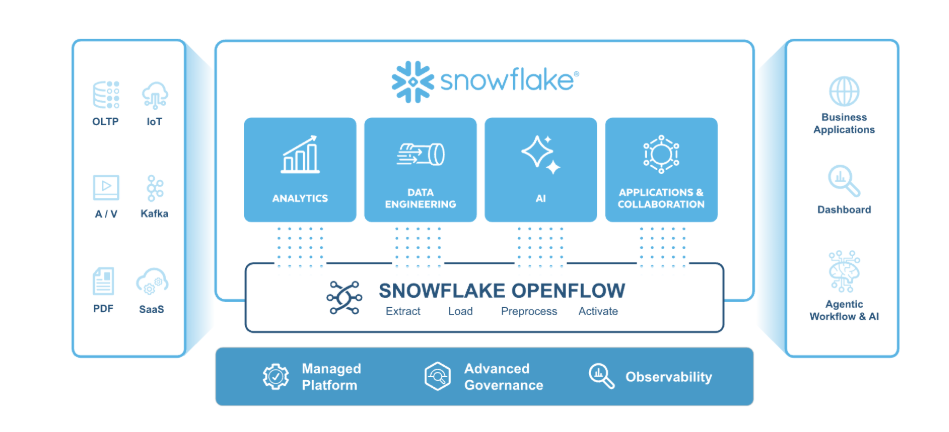
Everything has to be headless to work with coding agents; it’s just the way the world is going. A year after introducing OpenFlow (the managed NiFi-based ingestion service), Snowflake is filling in the gaps. There's now a programmatic API and object model to configure OpenFlow, so you can build and manage pipelines as code instead of clicking through a UI (and yes, CoCo can do this for you). For the security-conscious, an OpenFlow Data Connectivity Proxy brings private connectivity to your sources. And the connector library keeps growing: the Oracle connector is now GA (agentless CDC via Oracle XStream), with Veeva, BigQuery, and MongoDB connectors in public preview.
Snowflake AIM (AI-powered Migrations) - GA

Snowflake has unified all of its migration efforts (SnowConvert AI, the Snowpark Migration Accelerator, and the Datometry technology) under one banner: AIM, AI-powered Migrations, and it's now Generally Available. A migration agent inside CoCo handles assessment, conversion, validation, and deployment, and Snowflake claims it can accelerate code migration by an average of 88%. From what I can tell, practically speaking this is a Plugin for CoCo, which amounts to a set of skills and connectors to legacy systems.
Operational Data
Snowflake Postgres Updates
Snowflake Postgres, the fully managed PostgreSQL service that went GA in February, picked up a wave of enterprise hardening this year: Private Link support, customer-managed keys, and secrets, so the safety capabilities you expect from Snowflake now extend to your operational database. Snowflake also open-sourced a managed version of PG Lake earlier this year, an extension that synchronizes Postgres data into an open, interoperable lake, going GA later this year.
Postgres Data Mirroring - Public Preview

The real-time replication story a lot of teams have been waiting for. Flip a switch to mirror a table from Postgres into Snowflake and Snowflake handles the change data capture and synchronization at very low latency, with no extra tooling required. It lands operational data in your analytics environment without standing up a separate CDC pipeline.
Compute and Performance
Adaptive Compute goes GA
The big economics story. Adaptive Compute, the service that ends warehouse t-shirt sizing by automatically figuring out the right amount of compute for each query, is moving into General Availability (rolling out soon). Snowflake says the new model is roughly twice as fast as the original generation-one warehouses. If you've ever agonized over whether a job needs an XS or a Large, the pitch is that you stop thinking about it: Snowflake right-sizes the compute and bills you only for what you use.
Interactive Compiler

One of the more under-the-radar but genuinely exciting launches. Snowflake introduced a brand-new interactive query compiler. Every query spends time compiling before it spends time executing, and this new compiler is far more memory efficient. With the usual disclaimers about absolute numbers, Snowflake said early workloads with one of its largest customers showed a 40x faster compile time, which accelerated that customer's overall workload by 3 to 4x. The team's stated goal is that you should never have to think about compile time in Snowflake again.
Interactive Workloads and a faster Unistore
Interactive tables and interactive warehouses launched in December 2025, and at Summit Snowflake added new cluster sizing, key selection, and pre-caching on top of them. CoCo now has skills to help with optimization and key selection to help you tune these.
Unistore Engine Optimization — Public Preview

If you haven't looked at Unistore since it launched, now is the time. A quick refresher: Unistore is Snowflake's answer to the classic problem of running separate transactional (OLTP) and analytical (OLAP) databases. Powered by hybrid tables, it uses a dual-storage architecture, row-based for fast single-row reads and writes, columnar for analytics, so you can handle both workloads on the same data inside Snowflake without ETL between systems. The catch has always been performance. At Summit, Snowflake announced a major engine optimization that improves latency and throughput by roughly 8x. If you tried hybrid tables early and walked away, it's worth revisiting.
AI Functions and Cortex
AI_COMPLETE now reads audio and video
Cortex AISQL continues to be one of the most common ways people actually use AI on their data, and the big addition this year is that AI_COMPLETE now accepts audio and video as inputs, not just text and images. Sentiment, classification, content insights: the multimodal use cases keep compounding, and it's all still just a SQL function call.
Cortex AI Function Studio
This is a major announcement. If AI functions are how you interface with models, Cortex AI Function Studio lets you build your own specialized AI functions: create a function, evaluate it, and control exactly which AI operations the users of your platform are allowed to run. This is a nice governance and standardization story: instead of everyone hand-rolling prompts, your platform team can publish vetted, evaluated functions. It's in Public Preview.
Grok comes to Cortex
Snowflake's standing promise is to always offer the latest and greatest models, and this year that means xAI's Grok models are now available in Cortex (the keynote's "SpaceX AI" phrasing threw a few people, but it's xAI). They join Anthropic, OpenAI, Google, Meta, Mistral, and DeepSeek. The pitch is that Grok is increasingly competitive on both price and performance, and model choice in Cortex means if something better shows up tomorrow, Snowflake brings it to you.
Agentic Search
Cortex Search already lets you do semantic retrieval over unstructured data, finding the most relevant chunks of text for a given question. Agentic Search handles a different problem: what if you need a precise, analytical answer rather than a ranked list of documents? Instead of returning relevant text, it uses AI functions to extract structured facts out of your unstructured documents and then runs an actual analytical query on them. "How many contracts are dated in 2025?" comes back as a number, not a pile of contract excerpts. It's available through CoWork and Cortex Agents.
Code Bundles - Public Preview
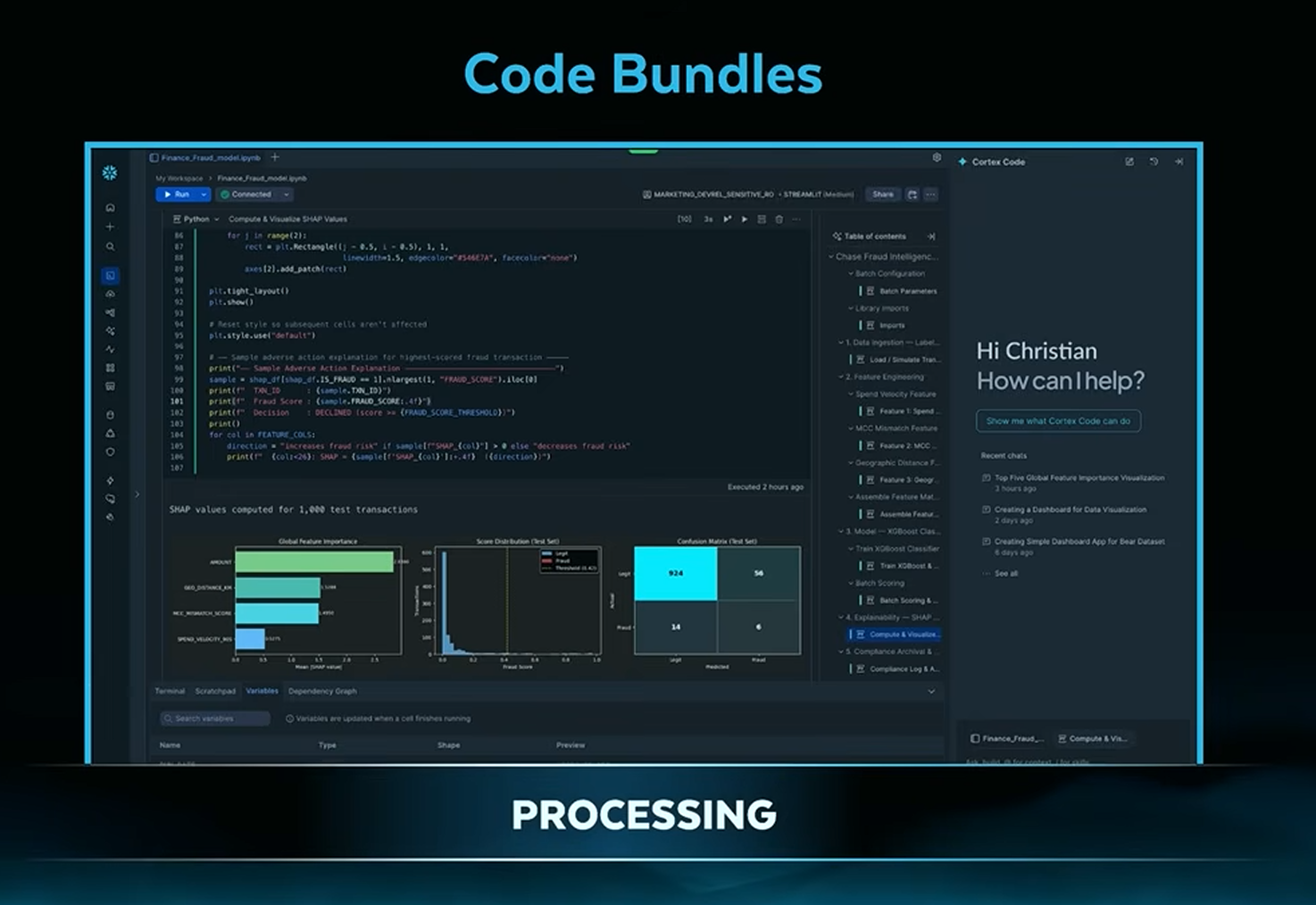
Today, if you have a Python script you want to run inside Snowflake, you can't just hand it over. You have to wrap it in a stored procedure, deal with staging, manage permissions, and paste or reference the code in a way Snowflake understands. Code Bundles skips all of that. You point Snowflake at your Python or Java file and run it directly, the same way you'd run it locally. What a concept! You can execute it on demand or put it on a schedule. It's a small change in theory but a meaningful quality-of-life improvement if running code inside Snowflake is part of your daily workflow.
Machine Learning
Cortex Training
Snowflake quietly has a full ML stack, and this year it gets a real model-customization story. Cortex Training is a fully managed GPU service for fine-tuning or reinforcement learning on open-weight foundation models, right where your data lives, with no data movement and no distributed-infrastructure babysitting. Snowflake says it can squeeze meaningfully more training runs out of a given GPU budget through higher utilization. It's in Private Preview.
Snowsight Pipeline Builder — Private Preview
A visual DAG editor for orchestrating Notebooks and ML Jobs directly in Snowsight. You can see your pipeline as a graph, edit it visually, bootstrap it from an existing notebook or ML package, and inspect errors without digging through logs. It's aimed at the ML lifecycle rather than general data transformation — think training pipelines and model workflows, not dbt or Dynamic Tables.
A few more ML wins
Snowflake also shipped VS Code and Cursor extensions for building ML pipelines against remote Snowflake compute, online A/B testing for running controlled model experiments on live traffic before you promote a winner (Public Preview), and streaming feature serving that serves online feature vectors in roughly ten milliseconds; that one is going GA.
Apps and Consumption
Streamlit in Snowflake (container runtime) goes GA
Streamlit is how a huge number of developers build data experiences on Snowflake, and the container-runtime version of Streamlit in Snowflake is now GA. It runs in containers, integrates with Workspaces and Git, and is faster and cheaper than before. If you've been building Streamlit apps in Snowflake, this is the version you want.
Snowflake App Runtime
For teams that want more control than Streamlit gives them, Snowflake App Runtime lets you run Node.js (and soon Python), so you can deploy a full React application inside Snowflake's security perimeter, RBAC and all. Once it's built, the easiest path to deploy is a one-line snow app deploy from the Snowflake CLI (and naturally, CoCo can build and deploy it for you). It's in Public Preview.
Snap and Ask
A small but delightful CoCo feature: Snap and Ask lets you select any chart, table, or card on screen and ask CoCo about it, grounded in the live data behind it. It's the kind of thing that makes the platform feel like it's paying attention.
Interoperability and Data Sharing
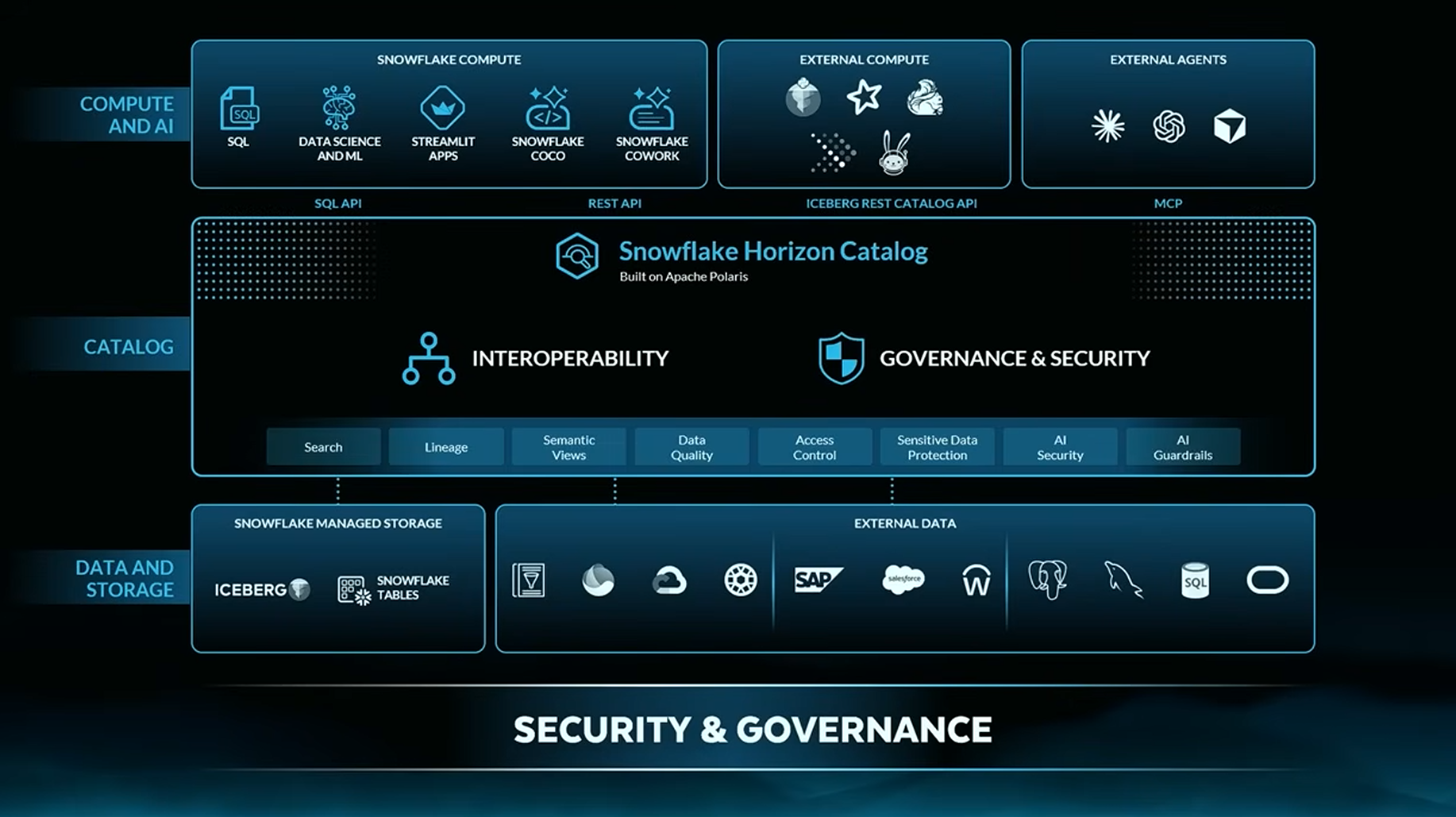
Apache Iceberg V3 - GA
Snowflake now has the broadest implementation of the V3 spec and is helping shape V4. It has folded the Iceberg REST catalog interfaces from Apache Polaris into the Horizon Catalog, with full bidirectional read/write between catalogs and engines, so you can read and write data whether it's managed by Horizon or an external catalog.
Snowflake-managed Storage for Iceberg Tables - GA on AWS and Azure
GCP is coming shortly. Snowflake now manages the storage layer for your Iceberg tables directly, so you don't need to bring your own object storage to get Iceberg's open-format benefits inside Snowflake.
Data Resharing - GA
You can now freely reshare data that someone shared to you. Sounds simple, but this has been a longstanding gap.
Open Sharing - Public Preview
Share data with consumers who aren't on Snowflake at all, via Iceberg and the Iceberg REST catalog API. Providers share once, consumers access from anywhere.
Multi-party Collaboration - GA
Multiple parties can now collaborate in a single secure environment with different roles, some contributing data and some running analytics. Built on Snowflake's clean room technology. Netflix is an early adopter, building clean rooms with partners.
Zero-copy Integrations
Snowflake keeps expanding its zero-copy partnerships to unsilo SaaS data without ETL. The SAP integration is now GA. New additions include Workday Data Cloud, IBM watsonx.data (mainframe and DB2 data), and AVEVA Connect for industrial data.
Query Across External Sources

For data that lives in systems Snowflake doesn't manage at all, CoWork can now query across Redshift, Postgres, and other external sources, bringing Snowflake AI to data without moving it.
Snowflake CoCo (formerly Cortex Code)

CoCo has only been around since early 2026 and is already, per Snowflake, the fastest-growing product in its history. This Summit it grew up a lot.
Cloud Agents and Automations
The headline is Cloud Agents: every Snowsight session can now spin up an isolated, Snowflake-managed sandbox that runs shell commands, Python, package installs, dbt builds, and web browsing, bringing the full power of the CLI into Snowsight with zero local setup. There's a matching sandbox for the local CLI environment too. On top of that, CoCo gets Automations: recurring, autonomous, scheduled workflows via async APIs.
Skill Catalog - Public Preview
A catalog for discovering, sharing, and reusing skills and plugins across teams. Build a skill once, publish it, and anyone in your organization can find and use it.
CoCo is Desktop and much more
CoCo is showing up everywhere you work. CoCo for Desktop is now GA, and CoCo is now available as a VS Code extension, a Microsoft Excel plugin, and a plugin for Anthropic's Claude Code, with mobile and a Slackbot on the way.
Snowflake CoWork (formerly Snowflake Intelligence)
If CoCo is the builder's control plane, CoWork is meant to put an agent in front of every single person in your organization. Kleinerman's framing was that everyone gets their own pit crew, or their own Jarvis. The big shift this year is personalization.
Personal Work Engine
The centerpiece of this year's CoWork release. CoWork removes the old agent picker entirely. Instead of making users choose which agent to talk to, there's now a single personal agent that does multi-agent orchestration, routing each request to the right data, skills, and tools behind the scenes. It's backed by User Memory that learns each person's patterns and preferences, plus personal skills and personal MCP connectors (email, Slack, Teams, calendar) so the assistant adapts to how you actually work. You also get scheduled tasks and automations (a daily brief in your inbox at 6am, a weekly analysis delivered automatically) without re-prompting every day.
Next-generation Artifacts
Snowflake is replacing their “Dashboards” product with Artifacts. These are governed, shareable views of live, trusted data that colleagues can interact with and ask follow-up questions of. But here’s the interesting part, you can only create and edit these using CoWork and CoCo.
Cortex Sense - Private Preview
The most interesting CoWork announcement might be Cortex Sense, a runtime capability that automatically makes agents smarter by gathering context and building signals from the data and activity already in Snowflake: query history, dashboards, metadata, agent trajectories. It knows that a data scientist and a sales VP want different answers to the same question. It works for both CoCo and CoWork, and Snowflake's internal testing showed accuracy jumping to 83% with Cortex Sense versus 47% without it on the same eval set. Your mileage will vary, but the direction is exactly right: context, not raw model horsepower, is what makes enterprise AI useful.
Governance and Trust (Horizon)
Trust was a whole act of the keynote, and it all runs through the Horizon Catalog.
Intent-Driven Governance - Private Preview
The most forward-looking launch in this section and a favorite of mine. You express intent in natural language ("take all the PII in my database and make sure it's protected"), and Snowflake handles the details, triggering classification, creating the right policies, and keeping things governed over time as new objects appear. You say what you want; Horizon figures out how.
Horizon AI Guardrails - GA
Horizon AI guardrails are now built into both CoCo and CoWork to detect and block prompt injection and jailbreak attempts, including zero-day attacks.
Agent Identity
Agent Identity gives every agent a verified identity and exposes a context function you can use inside masking or row-access policies, so you can give an agent more or less visibility than the human running it.
Data Movement Policies - Private Preview
Data Movement Policies let you declare that data with a given tag can't move to an internal or external stage or be downloaded through the Snowsight UI, regardless of which tool initiates the transfer.
Trust Center: Data Exfiltration Detection - Public Preview
A new detection package in Trust Center monitors for unusual data transfers leaving your perimeter, giving you visibility into whether data is moving outside your secure environment.
Multi-Party Approval - Public Preview
Requires a mandatory second-person sign-off on the highest-risk operations (like disabling MFA org-wide), so a rogue insider or a misbehaving agent can't act alone.
AI Security Posture Checks - Public Preview
A broader set of checks in Trust Center that validate your agents and AI are configured to best practice, with continuous monitoring of agentic security posture.
Horizon Context
Underneath all of this is Horizon Context, a part of the Horizon Catalog that collects and enriches signals and metadata and serves them to CoCo, CoWork, and Cortex Agents so they actually understand your business. It ships with metadata connectors that pull context from BI tools, transformation tools, and other databases, and it folds in all the ongoing semantic views work, including auto-generation of semantic views from your existing SQL, Tableau, and Power BI assets.
Cost Governance and Business Continuity
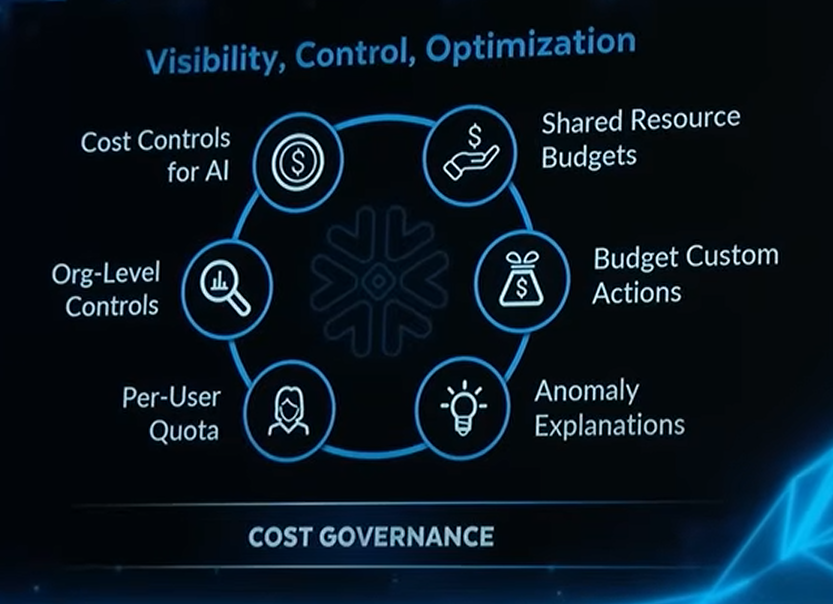
AI Cost Controls
Kleinerman spent real time on cost, repeating the line that Snowflake doesn't want you spending a dollar you're not getting value back from. On that front there are several additions: AI cost controls that respect your existing budgets, per-user quotas, cost governance on a shared warehouse (so you can attribute spend across departments or users sharing one warehouse), and budget custom actions that let you invoke a stored procedure or other activity automatically when a spend threshold is hit.
Next-Generation Account Replication

Snowflake introduced the next generation of account replication, which is log-based and roughly 20x faster than before. That speed lets Snowflake offer an SLA-backed RPO assurance, standing behind the data gap on a failover. For context on why this matters, Snowflake noted that during a cloud-provider outage last year, over 300 customer workloads failed over with nothing to see and business kept running.
Observe by Snowflake
The Observe acquisition that Snowflake completed earlier this year is starting to pay off. Observe brings logs, application performance monitoring, and infrastructure monitoring into a Snowflake-native observability solution with a competitive cost structure. It now has a CoCo interface and a CLI for configuring, triaging, and investigating alerts, and it runs on Snowflake Iceberg tables.
The Natoma Acquisition
Kleinerman closed the product story with an acquisition. Natoma is an enterprise Model Context Protocol platform, and it gives CoCo and CoWork a governed MCP gateway with roughly 100 business-system connectors out of the box: Slack, CRM, Jira, internal APIs, databases. The point is to extend Snowflake's governance from data access all the way out to agent actions across external systems, with identity verification and auditability at the tool-call level. This is the connective tissue that lets an agent inside CoWork send an email, summarize a Slack thread, or open a Jira ticket without ever leaving Snowflake, and without your security team losing sleep.
Minor Announcements and Status Changes
A number of features Snowflake highlighted were already announced previously and reached GA (or otherwise changed status) at Summit. Grouping them here so the new stuff above stays front and center:
- Oracle OpenFlow connector: now GA (agentless CDC via Oracle XStream).
- Snowflake Postgres (core managed service): GA since February, now with Private Link, customer-managed keys, and secrets.
- Adaptive Compute: moving to GA (rolling out soon), roughly 2x faster than gen-one warehouses.
- Apache Iceberg V3: GA, with bidirectional read/write via Polaris in the Horizon Catalog.
- Snowflake-managed Iceberg storage: GA on AWS and Azure (GCP coming shortly).
- Multi-party collaboration / clean rooms: now GA.
- Data resharing: now GA.
- SAP zero-copy integration: now GA.
- Streamlit in Snowflake container runtime: now GA.
- CoCo for Desktop: now GA.
- ML feature serving / streaming features: going GA (sub-2-second freshness, ~10ms serving).
- CoWork core capabilities: skills, MCP connectors, Deep Research, the iOS mobile app, and reusable artifacts, all introduced over the prior months and now reaching GA.
- Cortex AISQL: GA across text, documents, images, audio, and video.
- Semantic View Autopilot: GA (auto-builds semantic views from SQL, Tableau, and Power BI).
- Dynamic Tables performance: GA, with notably faster refreshes.
Wrap Up
Last year Snowflake unified the data; this year it's unifying the work. The throughline of Summit 2026 is that models are becoming a commodity, and the real moat is governed enterprise data plus the context and identity that make agents trustworthy. CoCo and CoWork are the two faces of that bet (one for the people building the platform, one for everyone trying to get answers out of it), and almost everything else announced exists to make those two surfaces faster, safer, and smarter. A lot of the headline features are still in preview, so the next few quarters will tell us how much of this lands as promised. But the direction is unmistakable, and we're excited to see what you build with it.

Jeff is a Data and Analytics Consultant with 15+ years experience in automating insights and using data to control business processes. From a technology standpoint, he specializes in Snowflake + dbt + Tableau. From a business topic standpoint, he has experience in Public Utility, Clinical Trials, Publishing, CPG, and Manufacturing. Reach out any time, [email protected].
Want to hear about our latest data cloud learnings?Subscribe to get notified.
Get up and running in less than 15 minutes
Connect your Snowflake, Databricks, or BigQuery account and instantly understand your savings potential.

