

What's New in Snowflake: Summer 2025
Jeff SkoldbergFriday, September 19, 2025
This month’s edition of "What's New in Snowflake" combines updates from July and August 2025. July was a fairly light month following Snowflake Summit in June, so we decided that one big article for two months was the way to go. That said, this is a BIG article. There’s something in here for everyone, so make sure to use the Table of Contents in the sidebar to find what interests you.
Snowsight
New sidebar (Preview, rolling out now)
Snowflake is rolling out a reorganized left navigation sidebar. Some accounts already have it, others will switch over in phases. From what I’ve seen, most accounts have it by now. The menu groups are cleaner and match how teams work. For me it took some getting used to. It took a few seconds to find “databases” and “query history”, but overall I love the new layout!
Layout:
- Shortcuts: pin up to three pages for quick access. Drag to reorder.
- Work with data: Projects, Ingestion, Transformation (dbt, Task History, Dynamic Tables), AI & ML, Monitoring (query history! Also GUI view of your event table is here), Marketplace.
- Horizon Catalog: Catalog (databases are here!), Data sharing, Governance & security.
- Manage: Compute and Admin.
Here is how you pin and unpin shortcuts:
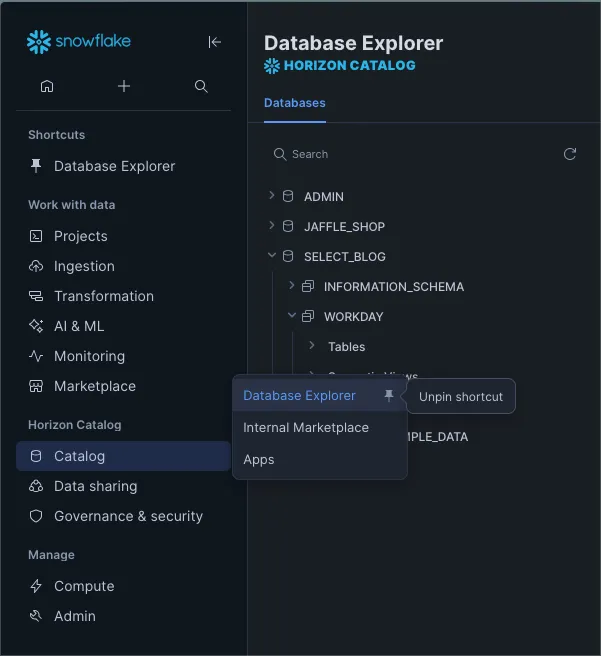
This screenshot, taken from Snowflake documentation, shows the new and old sidebar side-by-side.
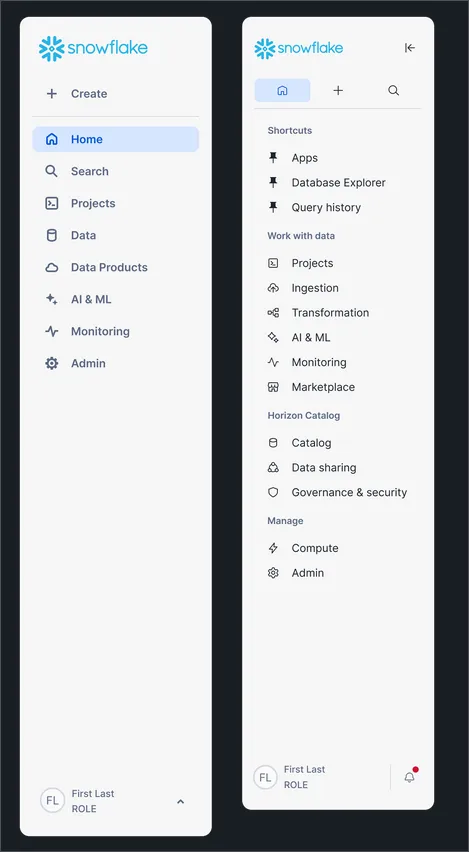
By the way, if you haven’t tried the new global search yet, you must try it! It will search across databases, marketplace, documentation, or really anything in Snowflake to find your keywords. I’ve found it very helpful to find what I’m looking for very quickly.
Use Snowsight to create a Semantic View (Public Preview)
You can create and manage Semantic Views directly in Snowsight via the database object explorer or the Cortex Analyst page. You can use the wizard or YAML upload.
- Start points:
- Old Sidebar: Data → Databases → Select a schema → Create → Semantic View, or AI & ML → Cortex Analyst → Create / Upload YAML.
- New Sidebar: Horizon Catalog → Catalog → Database → select a schema → create, Semantic View
- Or from AI & ML → Cortex Analyst
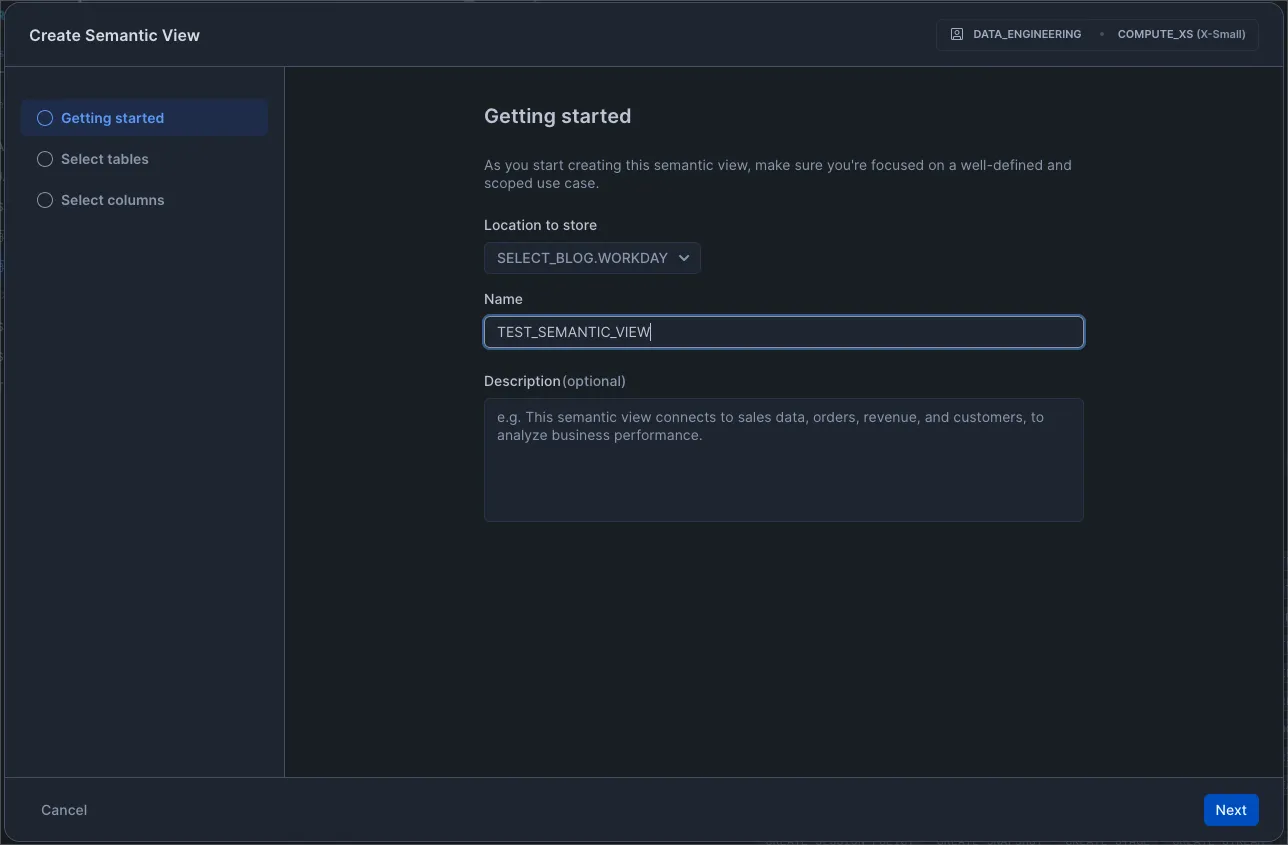
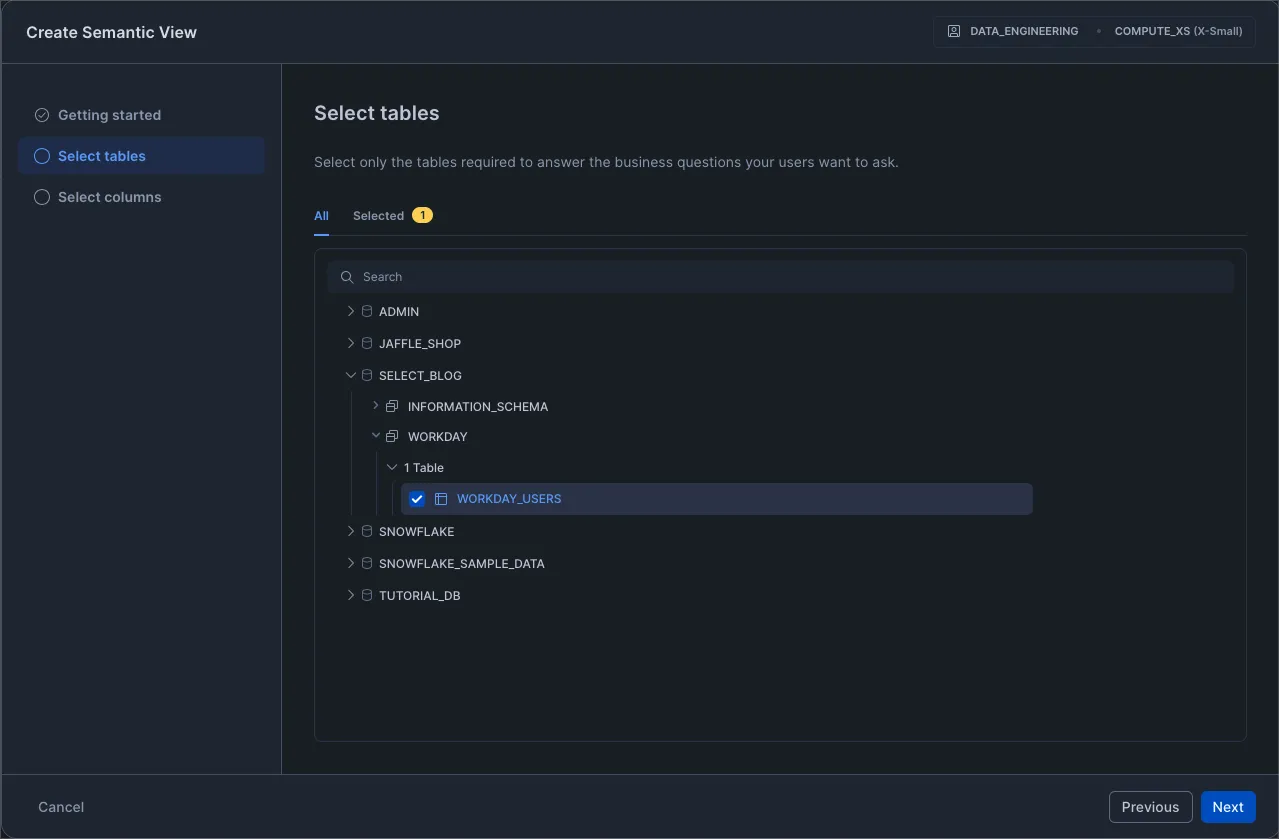
I found it very easy to create a new Semantic view. The screenshots below describe the process.
Step 1: Navigate to a Schema and click “Create”. Below shows the new sidebar, databases and schemas are now found in “Horizon Catalog”.
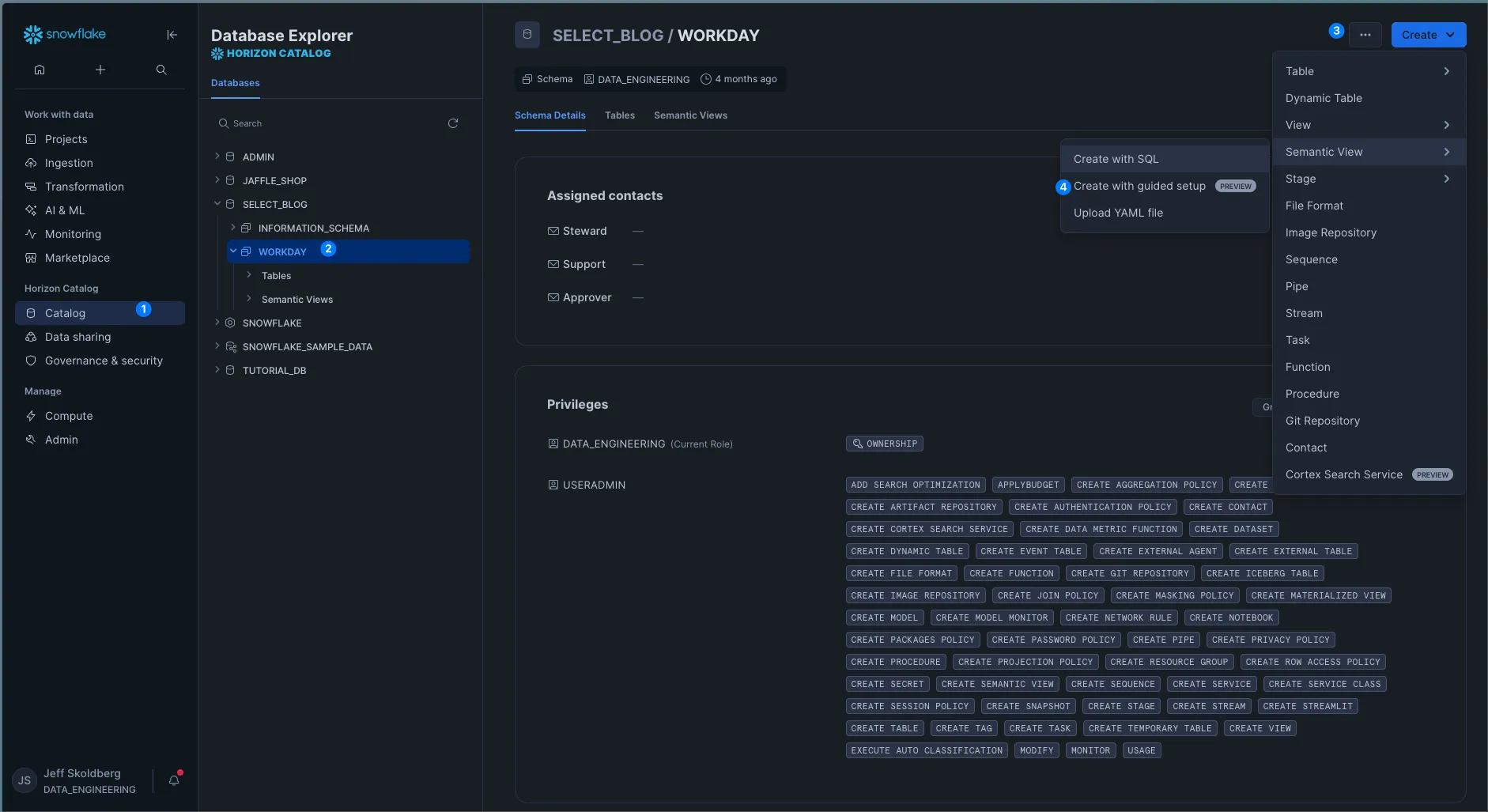
Step 2: Fill out the form pages
Here’s how you can do the same thing from the Cortex Analyst menu:
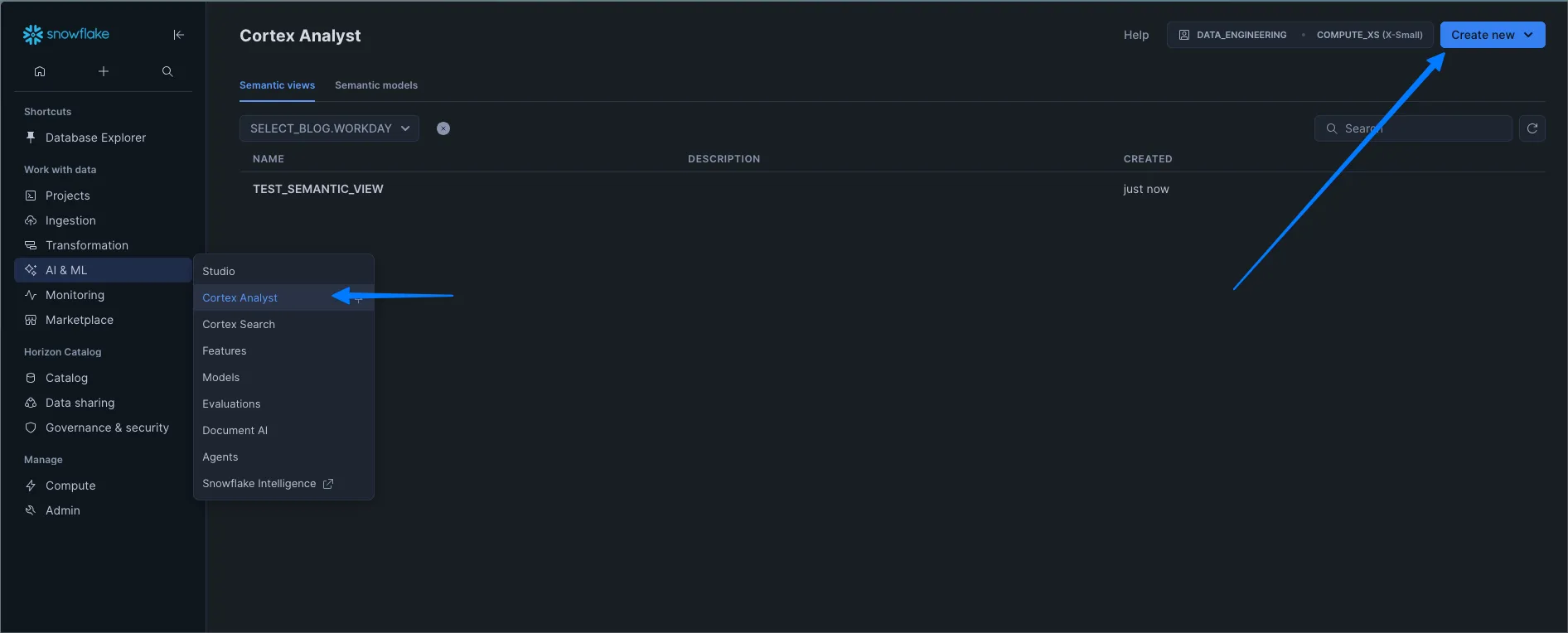
Note: querying semantic views with SQL is also in Preview. Check the docs for more info.
Data Engineering, Pipeline, and SQL Updates
Dynamic Tables: read from externally managed Iceberg (GA)
Dynamic tables can now read directly from Iceberg tables managed by an external catalog. This is a significant improvement to Snowflake’s data pipeline features for customers leveraging Iceberg. More info can be found in the docs.
Structured types for standard tables (GA)
Other data platforms like Big Query and Databricks have long offered structured data types (struct, array, record), while Snowflake has only offered the variant data type to cover this use cases.
Now, you can define ARRAY, OBJECT, and MAP as structured columns in regular Snowflake tables, with up to 1,000 sub-columns per column. At this time, structured types aren’t supported on dynamic, hybrid, or external tables. See the docs for more
Pre-clustering for Snowpipe Streaming (Preview)
Snowpipe Streaming can pre-cluster rows at ingest so data lands sorted by your clustering keys, improving query performance on hot tables and reducing the load on automatic clustering. We have not tested this yet, but this is likely going to be a cost savings tactic for customers who have high automatic clustering spend.
Enable pre-clustering in the COPY definition with CLUSTER_AT_INGEST_TIME=TRUE; your target table must already have cluster keys.
COPY FILES command (GA)
COPY FILES moves objects across from one stage to another. A real-life use case of this feature is moving files from an “unprocessed” to a “processed” folder.
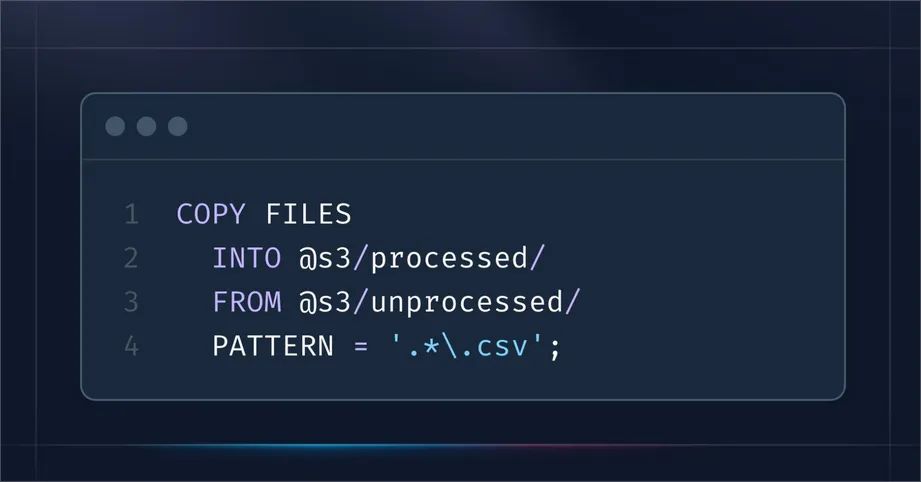
In this scenario, you can set bucket policies (outside of Snowflake) to ensure your unprocessed folder gets cleaned up after a certain amount of time, without adding extra code to manage data lifecycle.
For example, you could have a policy to delete data from unprocessed after 30 days, and the policy on your processed data could archive it to Glacier after 60 days. This type of strategy reduces data duplication and storage costs outside of Snowflake.
Run tasks as another user: EXECUTE AS USER + IMPERSONATE (GA)
Tasks can run with a specific user’s privileges using EXECUTE AS USER, once the task owner role has IMPERSONATE on that user. This is useful when downstream policies or systems depend on user identity for things like row access or masking, and it makes it easier to see who a task really acted as when you look back in the logs.
Below is a simplified example to demonstrate the new feature. The example assumes users and roles already exists. See Snowflake docs for a complete example including creating the users, roles, warehouses, task grants, etc.
The new Snowpipe pricing announced at Summit: Now GA for Business Critical and VPS
In our Summit Recap we’ve already discussed that the new Snowpipe pricing model will be a win for customers. The old Snowpipe pricing had two components: per-second per-core and per 1000 files. The new pricing is simplified: a fixed credit amount per GB ingested.
This has now gone from concept to GA for Business Critical and VPS customers, and will soon roll out for Standard and Enterprise customers.
To understand all of the details, you really want to review the credit consumption table and the Snowpipe cost docs.
Snowpark Connect for Spark and Snowpark Submit (Preview)
In the simplest terms, you can now run Apache Spark jobs directly in Snowflake without re-writing any code. This includes Spark DataFrame, SQL, and UDFs. You can also submit non-interactive jobs asynchronously via Snowpark Submit.
These features are a pragmatic bridge for Spark shops who are migrating to Snowflake and don’t want to rewrite Spark code into Snowpark APIs.
You can develop in familiar tools like Jupyter Notebooks or Snowflake Notebooks. Check the docs for more.
Snowflake Scripting UDFs (GA)
You can now use Snowflake’s Scripting logic in SQL UDFs and call them inline from queries, not only via CALL like stored procedures. This is great for small procedural helpers or custom SQL functions you want to reuse in SELECT/INSERT statement.
Snowflake Scripting is a powerful SQL scripting language. Full details on the new UDF feature can be found here.
It is worth noting that this will not work with cursors (declare … c1 cursor for select foo from bar). This limitation is probably a benefit to users, because row based logic like cursors are a bad idea for SQL functions.
Dynamic tables: UNION in incremental refresh (GA)
As customers continue to adopt Snowflake’s native data pipeline capabilities, Snowflake is closing one obvious and annoying gap: Incremental dynamic tables can now support UNION (distinct) in refresh queries, broadening the kinds of multi-source merges you can run without falling back to full refresh. Other set operators (example: minus, except, intersect) remain unsupported in incremental mode.
A tip for SQL beginners out there, it is considered best practice to prefer union all over union, because union forces a distinct, which slows down the query execution. So only use this new feature if you need the union to bedistinct.
As of today, the Snowflake docs have not been updated to include the support of union set operator, but this is in fact released. 🧐

Monitoring events for Snowpipe, plus Iceberg auto-refresh events (GA)
Snowpipe now publishes detailed ingestion events into the active Event Table. You can see when a pipe changes state, track per-file progress, and review periodic digests summarizing ingestion activity. On top of that, Snowflake also emits events whenever an externally managed Iceberg table is automatically refreshed.
The net result is that you can observe the full ingestion lifecycle, from staged files landing in Snowpipe to downstream Iceberg tables being kept current, all in one place. This closes a long-standing visibility gap. In practice, it should make troubleshooting stuck files or laggy refreshes much easier and open the door to tighter alerting around data pipeline SLAs. I think this is one of those “quality of life” features that may not sound flashy at first, but teams running production ingestion pipelines will immediately appreciate it.
Here’s more info on the feature.
Set a target file size for Iceberg tables (Preview)
You can now define a target Parquet file size when creating or altering an Iceberg table. This gives more control over how data is written and can improve performance when those files are read by engines like Spark or Trino.
It is especially useful in multi-engine setups where file size can make or break query efficiency. Smaller files suit fast, granular queries while larger ones cut down overhead for big scans. I see this as a practical step that makes Snowflake more flexible for hybrid lakehouse use.
Here’s an example of how to create or alter an Iceberg table using this new feature:
ALTER LISTING: simpler add/remove targets (GA)
Marketplace providers can now add or remove listing targets with a partial manifest instead of resubmitting the full target set. This trims automation complexity when managing many accounts, roles, or organizations.
AI and Semantic Modeling Updates
Private facts and metrics in semantic views (General Availability)
You can mark facts and metrics as PRIVATE when defining a semantic view. Private items are allowed in calculations inside the view but cannot be queried directly or used in filters. They still show up in DESCRIBE SEMANTIC VIEW and GET_DDL, which helps with discoverability and audits. This is useful when you want clean, business-ready metrics at the surface while keeping helper facts and intermediate metrics hidden. My take: this is a gap I never realized existed, but makes semantic views feel more production-friendly for governed analytics.
AI_EXTRACT function (Preview)
AI_EXTRACT pulls structured fields from unstructured inputs. It works on strings or FILE inputs, and you define the response format with simple prompts or name-prompt pairs. Think invoices, contracts, patient notes, or marketing PDFs, all extracted directly inside Snowflake. This results in fewer round trips to outside services and a simpler path to landed, structured data. This promising for teams already centralizing data in Snowflake, but treat it like any preview AI feature. My approach would be to start with a labeled test set to see how it performs. Think about what guardrails you want to add before you wire it into critical pipelines!
Examples:
AI Parse Document layout mode (GA)
AI_PARSE_DOCUMENT layout mode is new GA feature which replaces the SNOWFLAKE.CORTEX.PARSE_DOCUMENT function. It extracts a document’s layout into Markdown that preserves text flow, tables, and structure. Simply put, PDF (or similar) to Markdown! 🥳 That gives you a clean intermediate form for chunking, RAG, or downstream parsing. It seems this layout-aware parsing is the foundation for reliable document AI. I can also imagine pairing this with with AI_EXTRACT to go from raw files to structured rows with fewer steps.
ML
Distributed processing in Snowflake ML: Many Model Training and Distributed Partition Function (General Availability)
Snowflake ML now supports two distributed patterns. Many Model Training (MMT) trains separate models per partition of a Snowpark DataFrame in parallel. Distributed Partition Function (DPF) executes your Python function across partitions on one or more nodes in a compute pool, with artifact storage and progress tracking handled for you. This removes a lot of orchestration work while scaling out on the platform you already use.
If you’re curious to learn more Train models across data partitions and Process data with custom logic across partitions are thoroughly documented.
Data Quality, Observability, and Governance
Data Metric Function: ACCEPTED_VALUES (GA)
ACCEPTED_VALUES is a system DMF that validates whether a column’s values match a Boolean expression and returns the count of rows that do not. You associate it to a table or view on a schedule or run it ad hoc with SYSTEM$DATA_METRIC_SCAN.
This is a low effort and high value way to catch simple conformance issues like enums and code sets without custom SQL.
Snowflake Data Clean Rooms updates (GA)
A data clean room is a secure environment where multiple parties can analyze combined datasets without directly accessing each other’s raw records. This is done through strict query controls and policies that only allow approved outputs like aggregates or anonymized results, never row-level data.
Snowflake rolled out 4 data clean room updates last month. These updates are essentially quality of life updates that remove friction to using data clean rooms.
- Simplified flow for cross-region sharing: Providers no longer need to call both
request_laf_cleanroom_requestsandmount_laf_cleanroom_requests_shareto accept consumer requests from another region. Now they can just useprovider.mount_request_logs_for_all_consumers. This is shown in the developer guide under “Implementing activation in your clean room”. - Simplified installation: Snowflake now auto-creates and verifies the service user needed for clean rooms, or reuses an existing one, instead of making users do it manually. That means fewer setup steps before you can actually start using clean rooms.
- Single-account testing: You can now use a single Snowflake account to act as both provider and consumer in a test clean room. This is great for for dev/test environments so you can build and validate clean room templates without having to spin up separate accounts. The tutorials & samples page shows this in action (“Basic UI tutorial, single account”). See docs for a faster read.
- Configurable refresh rates for Cross-Cloud Auto-Fulfillment: By default, data refresh between provider accounts and consumer accounts in different cloud or region is now every 30 minutes (down from 24 hours). And you can configure that rate. See docs.
Write Once, Read Many (WORM) Snapshots (Preview)
WORM Snapshots are point-in-time, immutable backups of tables, schemas, or databases. They use snapshot sets and optional snapshot policies for scheduling and expiration. Retention lock and legal holds add protection against deletion, with retention lock designed for strong compliance guarantees. Not even accountadmin can drop these tables, so this gives strong protection against compromised credentials and ransomware. WORM Snapshots are available to all editions, with retention lock and legal holds for Business Critical and above.
This is a practical control for ransomware resilience and regulatory retention that goes beyond Time Travel. The feature seems promising for backup hygiene, but it’s still in preview, so test restore paths and plan storage before you lean on retention lock.
Snowflake Administration
Org profiles (General Availability)
You can now create and manage organization profiles in Snowsight, assign which accounts and roles can publish under a profile, and brand internal listings with a profile avatar and URL reference. This tightens trust inside the Internal Marketplace and removes a lot of one-off SQL for setup. It makes large orgs feel more organized and gives consumers clearer provenance for internal data products.
Tri-Secret Secure self-service activation (General Availability)
As a refresher from your Snowflake training, Tri-Secret Secure is Snowflake’s approach to encryption where three keys are involved: Snowflake’s own key, the cloud provider’s key, and a customer-managed key. Data can only be decrypted if all three are available, giving customers direct control to suspend access by disabling their key. It is available for Business Critical and VPS.
Using the new Self Service Activation feature, ACCOUNTADMINs can turn on Tri-Secret Secure on their own using system functions, manage the customer managed key, and even deactivate if needed. This cuts the support loop and makes strong encryption controls feel like a standard part of account hygiene, instead of a special project that involves customer support.
Query Insights: join performance and optimization (Public Preview)
Background:
Query Insights is a relatively new built-in feature that automatically surfaces findings about your queries, such as inefficient joins or missing filters. Instead of digging through raw profiles, you get human-readable hints that point you toward fixes that improve performance and lower costs.
Insights can be found in Snowsight Query History → Query Profile, or by querying the snowflake.account_usage.query_insights view. Using a 3rd party tool like SELECT gives users much better observability into query insights in a purpose built UI.
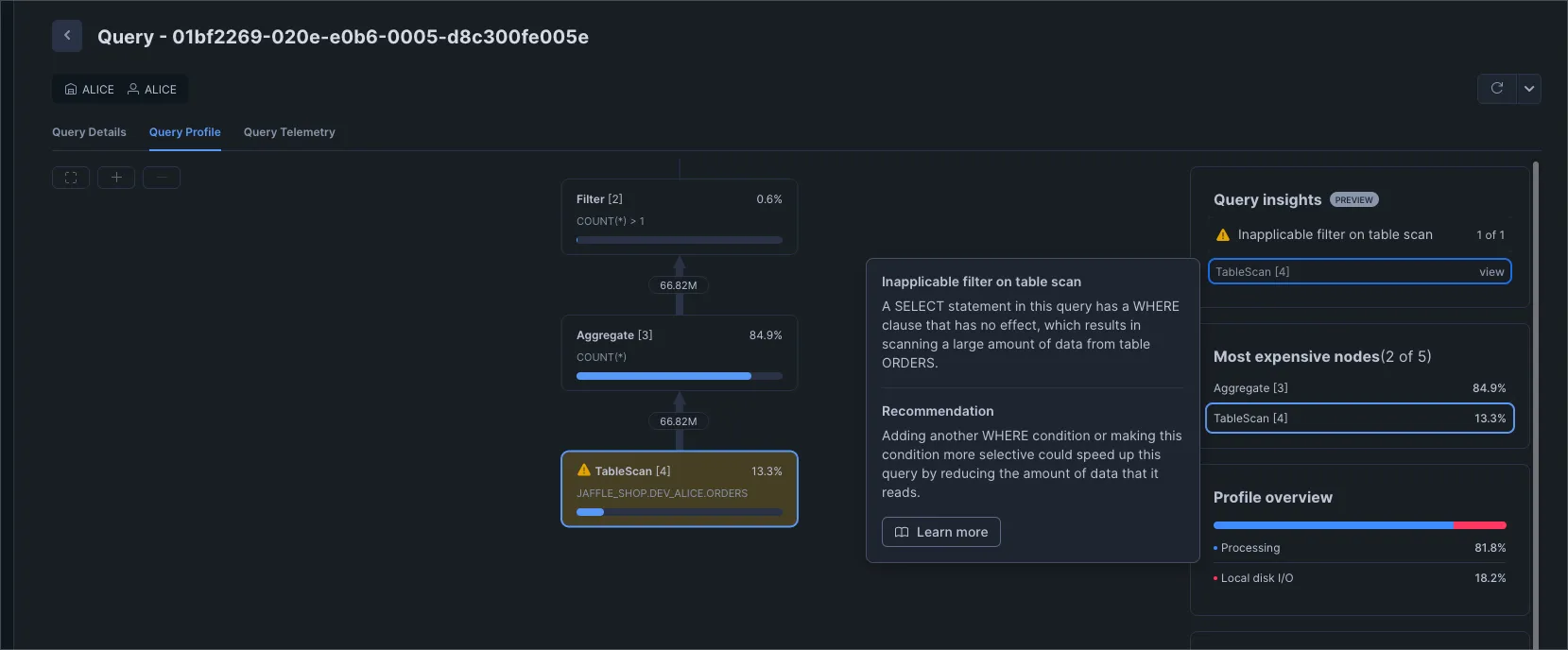
New feature:
Query Insights adds new findings for join mistakes and optimization wins, and you can see them in Snowsight or by querying the QUERY_INSIGHTS view. The hints call out patterns like missing join conditions, exploding joins, lack of filters, search optimization usage, and spillage so you can fix the root cause faster. This is quite useful for triage, even if you still lean on Query Profile for deeper dives.
Semantic views: list dimensions and metrics at any scope (GA)
You can inventory your semantic layer with SHOW SEMANTIC DIMENSIONS and SHOW SEMANTIC METRICS at any scope: view, schema, database, or account level, and even list which dimensions are valid for a specific metric. This helps you audit models, verify grain and relationships, and keep teams honest about what is actually available. This is a small feature but really nice to have for those in admin roles who rely on show commands to understand governance.
Other Updates
Here’s a quick list of other updates worth noting:
- Multi-Node ML jobs - Preview
- Create Index supports “Include Columns” - GA
- Consistency Secret now optional in generate_synthetic_data - GA
- Querying Semantic Views from Preview to GA
- The SEARCH_IP function supports searching for IPv6 addresses - GA
- Trust Center Emails moved from Preview to GA New Stage Volume for Snowpark Container Services - Preview
- Microsoft Power Apps Connector - GA
Wrap Up
Wow, that's a lot of features in two months! Let us know if you need guidance on any of these.

Jeff is a Data and Analytics Consultant with 15+ years experience in automating insights and using data to control business processes. From a technology standpoint, he specializes in Snowflake + dbt + Tableau. From a business topic standpoint, he has experience in Public Utility, Clinical Trials, Publishing, CPG, and Manufacturing. Reach out any time, [email protected].
Want to hear about our latest data cloud learnings?Subscribe to get notified.
Get up and running in less than 15 minutes
Connect your Snowflake, Databricks, or BigQuery account and instantly understand your savings potential.

